author: niplav, created: 2023-01-06, modified: 2025-09-17, language: english, status: maintenance, importance: 3, confidence: likely
Modeled after Gwern 2018 I've decided to log my nootropics usage and its effects. Includes three quantified self experiments, one on Caffeine, one on L-theanine, and one on Vitamin D₃.
You could put randomized substances in your body and find out what they do by recording the outcomes. That's what I did.
| Value tracked | Effect size d (200 mg Caffeine (n=11, m=502)) | Effect size d (500 mg L-theanine (n=1, m=50)) | Effect size d (25μg Vitamin D₃ (n=1, m=50)) |
|---|---|---|---|
| Log-score of prediction3 | -0.6 | -0.7 | -0.707 |
| Absorption | 0.70 | 0.05 | -0.04 |
| Mindfulness | 0.64 | 0.15 | -0.11 |
| Productivity | 0.64 | -0.21 | 0.04 |
| Creativity | 0.51 | -0.10 | -0.27 |
| Subjective duration | Not collected | 0.12 | -0.08 |
| Happiness | 0.26 | 0.03 | 0.003 |
| Contentment | 0.09 | -0.03 | 0.18 |
| Relaxation | -0.02 | -0.01 | -0.21 |
| Horniness4 | -0.07 | -0.01 | -0.19 |
| Flashcard ease | -0.012 | -0.073 | -0.006 |
| Flashcard ease factor | 0.001 | -0.017 | -0.011 |
| Flashcard new interval | 0.025 | -0.011 | 0.057 |
| Time per flashcard5 | -0.003 | -0.017 | 0.081 |
Hue indicates effect size, opacity indicates likelihood ratio (less opacity indicates higher likelihood ratio). Full table with sample sizes, likelihood ratios, changes in variance &c in this appendix.
I am especially interested in testing many different substances for their effect on meditation, while avoiding negative side effects. The benefits from high meditational attainments seem valuable to me, and could be especially likely to benefit from chemical intervention, since the Algernon argument likely doesn't apply: Meditative attainments might've not led to a fitness advantage (even, by opportunity cost, to a fitness disadvantage), and so were likely selected against, but most of us don't care that much about inclusive genetic fitness and more about psychological well-being. Evolutionary dynamics favor being like Ghengis Khan (dozens to hundreds of offspring) over Siddharta Gautama (one son), but I'd rather attain sotāpanna than pillage and murder.
And meditative attainments are costly: they take tens to hundreds to thousands of hours to reach, which would make simple psychopharmacological interventions worthwhile. I also don't buy that they miss the point of meditation—most people already struggle enough, so some help doesn't make it a cakewalk; "reach heaven through fraud". One must be careful not to fall into the trap of taking substances that feel good but lessen sensory clarity (which I believe was the original intent behind the fifth precept, and so I'll exclude e.g. opiates from the substances to test).
I won't dig too deep into the effects of caffeine, as other people have done that already (Examine, Gwern, Wikipedia).
Variables tracked (see more here):
The total cost of the experiment is at least 21.5€:
200mg caffeine pills, placebo pills filled with sugar, of each 25.
Put each pill with a corresponding piece of paper ("C" for caffeine,
"P" for placebo) into an unlabeled envelope. Used seq 1 50 | shuf
to number the envelopes, and sorted them accordingly.
Notes on the experiment:
In general, I'll be working with the likelihood ratio test (encouraged by this article). For this, let be the distribution of values of a variable for the placebo arm, and the distribution of values for a variable of the caffeine arm. (I apologise for the being ambiguous, since it could also refer to the control arm).
Then let be the Gaussian maximum likelihood estimator for our placebo values, and be the MLE for our caffeine values.
Then the likelihood ratio statistic is defined as
where is the likelihood the caffeine distribution assigns to the parameters . This test is useful here because we fix all values of . See Wasserman 2003 ch. 10.6 for more.
If , then the MLE for the placebo arm is very close to the MLE for the caffeine arm, the distributions are similar. If , then the MLE for the placebo arm is quite different from the caffeine arm (though there is no statement about which has higher values). is not possible, since that would mean that the MLE of the placebo distribution has a higher likelihood for the caffeine data than the MLE of the caffeine distribution itself—not very likely.
Note that I'm not a statistician, this is my first serious statistical analysis, so please correct me if I'm making some important mistakes. Sorry.
After collecting the data, but before analysing it, I want to make some predictions about the outcome of the experiment, similar to another attempt here.
Moved here.
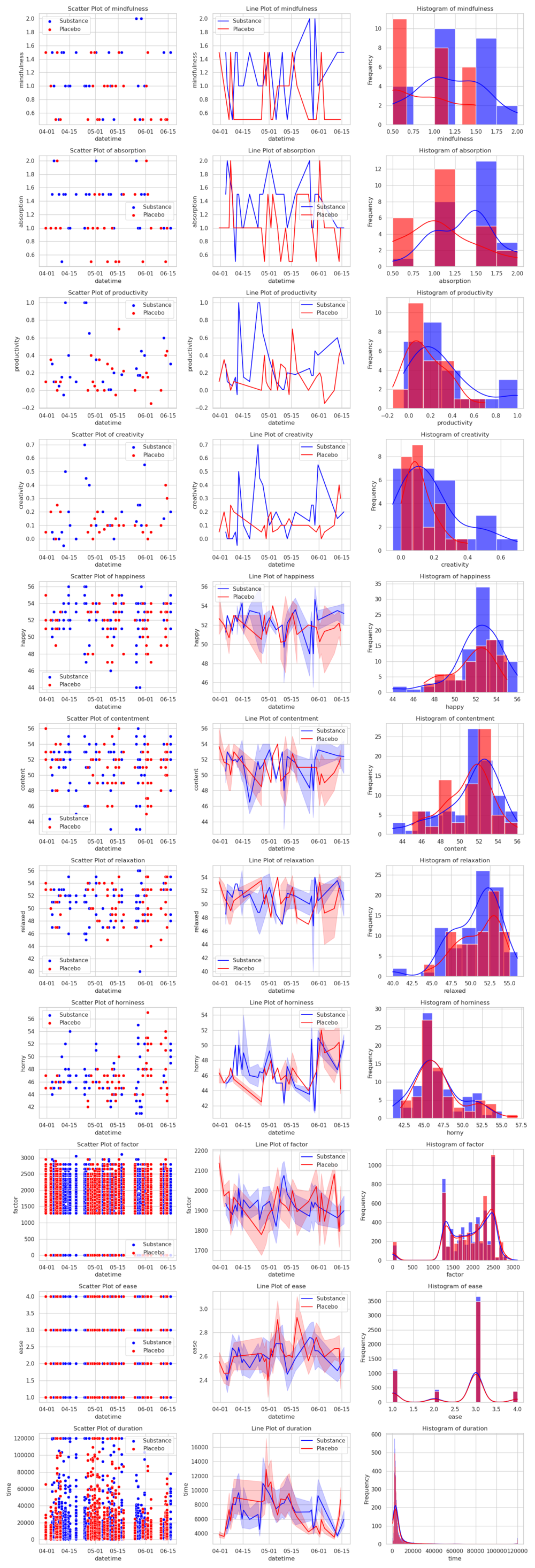
The analysis uses get_datasets and analyze from load.py. Plotting the raw data:
We can first test how well my predictions fared:
probs=np.array(expa['prediction'])
substances=np.array(expa['substance'])
outcomes=np.array([0 if i=='sugar' else 1 for i in substances])
drumroll
>>> np.mean(list(map(lambda x: math.log(x[0]) if x[1]==1 else math.log(1-x[0]), zip(probs, outcomes))))
-0.5991670759554912
At least this time I was better than chance:
>>> np.mean(list(map(lambda x: math.log(x[0]) if x[1]==1 else math.log(1-x[0]), zip([0.5]*40, outcomes))))
-0.6931471805599453
The full analysis code is in load.py, via get_datasets and analyze.
To analyze this specific experiment, I simply call
analyze(get_datasets('A', 'caffeine', 'sugar')) and get this nice
DataFrame:
absorption mindfulness productivity creativity sublen meaning happy content relaxed horny ease factor ivl time
d 0.698257 0.638603 0.639776 0.511584 NaN NaN 0.259945 0.086214 -0.021556 -0.068619 -0.011941 0.001465 0.025457 -0.002701
λ 13.3099 11.791 30.7593 56.343 0 0 10.8531 0.638312 0.187451 1.10841 2.97802 7.4239 4.16529 4.06691
p 0.00128764 0.0027518 2.093e-07 5.825e-13 1 1 0.00439824 0.726762 0.910533 0.574529 0.225596 0.024430 0.124600 0.130882
dσ -0.0720877 0.021868 0.107314 0.0982512 NaN NaN 0.304455 0.111812 0.153563 0.359615 -0.026015 -30.883 -5.26056 -651.043
k 50 50 50 50 0 0 180 180 180 180 10953 10953 10953 10953
m 50 50 50 50 0 0 49 49 49 49 50 50 50 50
control_m 25 25 25 25 0 0 24 24 24 24 25 25 25 25
intervention_m 25 25 25 25 0 0 25 25 25 25 25 25 25 25
Caffeine appears helpful for everything except relaxation (and it maybe makes me hornier, which I'm neutral about). I'd call this experiment a success and will be running more in the future, while in the meantime taking caffeine before morning meditations.
Examine. I follow the loading procedure detailed here:
Creatine is a supplement that is known for having a 'loading' phase followed by a 'maintenance' phase. A typical creatine cycle has three parts to it.
- Take 20-25g (or 0.3g/kg) for 5-7 days (Loading)
- Then take 5g daily for 3-4 weeks (Maintenance)
- Take a week or two off creatine, and then repeat (Wash-out)
First dose was taken on 2023-01-06.
I'm especially interested in the effects of creatine on my cognition (it might increase IQ in vegetarians (or it might not?), and I'm a lacto-vegetarian), my exercising performance and my meditation ability.
L-Theanine is synergistic with caffeine in regards to attention switching[318] and alertness[319][320] and reduces susceptibility to distractions (focus).[320][321] However, alertness seems to be relatively subjective and may not be a reliable increase between these two compounds,[318] and increases in mood are either present or absent.[322][318][323] This may be due to theanine being a relatively subpar nootropic in and of itself pertaining to the above parameters, but augmenting caffeine's effects; some studies do note that theanine does not affect the above parameters in and of itself.[324] Due to this, any insensitivity or habituation to caffeine would reduce the effects of the combination as L-theanine may work through caffeine.
L-Theanine does not appear to be synergistic with caffeine in regards to attention to a prolonged and monotonous task.[325]
—Kamal Patel, “Caffeine”, 2023
See again Examine, Wikipedia and Gwern.
Sitiprapaporn et al. 2018 test the effect of an unspecified quantity of L-theanine via Oolong tea on meditation on 10 university students (non-randomized, it seems). Data collected via EEG and indicates statistically significantly more alpha waves during meditation (although it is unclear how long the meditation was).
This paper is bad. The english is so horrendous it feels like I'm having a stroke while I'm reading it, but that would be fine if they were good at reporting methods, which they are not (missing amounts of L-theanine and duration of meditation, they also mention reading earlier in the article, which I assumed was the control activity, but it doesn't come up again?). Also they report differences between scores, not effect sizes, and some figures are screenshotted images from a Windows Vista clustering application.
Examine agrees on the cognitive effects of l-theanine (if not on meditation specifically):
L-Theanine supplementation in the standard dosages (50-250mg) has been repeatedly noted to increase α-waves in otherwise healthy persons. This may only occur in persons with somewhat higher baseline anxiety[25][26] or under periods of stress (positive[14] and negative[27] results), but has been noted to occur during closed eye rest[5] as well as during visuospatial tasks[16] around 30-45 minutes after ingestion.[5][4] It appears that only the α-1 wave (8-10Hz) is affected, with no influence on α-2 wave (11-13Hz).[4]
Bill Willis, “Theanine”, 2022
Although I'm confused about the increased α-waves in "otherwise healthy patients"‽
Additionally, it notes that memory was slightly increased:
One study using a supplement called LGNC-07 (360mg of green tea extract and 60mg theanine; thrice daily dosing for 16 weeks) in persons with mild cognitive impairment based on MMSE scores, supplementation was associated with improved delayed recognition and immediate recall scores with no effect on verbal and visuospatial memory (Rey-Kim test).[17]
Bill Willis, “Theanine”, 2022
This time I explicitely divided my meditation into a concentration part (first 15 minutes) and a mindfulness part (last 30 minutes).
Notes during consumption:
Ran the experiment from 2023-06-22 to 2023-09-28, sometimes with pauses inbetween samples.
I use the same statistical techniques as in the caffeine experiment, and start, as usual, with my predictions about the content of the pill:
>>> substances=pd.read_csv('../../data/substances.csv')
>>> experiment='B'
>>> substance='l-theanine'
>>> placebo='sugar'
>>> expa=substances.loc[substances['experiment']==experiment].copy()
>>> expa['datetime']=pd.to_datetime(expa['datetime'], utc=True)
>>> probs=np.array(expa['prediction'])
>>> substances=np.array(expa['substance'])
>>> outcomes=np.array([0 if i=='sugar' else 1 for i in substances])
>>> np.mean(list(map(lambda x: math.log(x[0]) if x[1]==1 else math.log(1-x[0]), zip(probs, outcomes))))
-0.705282842369643
This is not great. In fact, it's slightly worse than chance (which would be about -0.693). Not a great sign for L-theanine, and, in fact, it gets worse. I use the generalized and compacted code from the last experiments to get the other results, and they don't point a rosy picture for L-theanine:
>>> analyze(get_datasets('B', 'l-theanine', 'sugar'))
absorption mindfulness productivity creativity sublen meaning happy content relaxed horny ease factor ivl time
d 0.0455541 0.151308 -0.213726 -0.101527 0.123856 NaN 0.031822 -0.026932 -0.008843 -0.009361 -0.073231 -0.017276 -0.010971 -0.017431
λ 1.37829 0.72078 2.89777 5.25071 1.98097 0 1.12016 0.414468 0.172610 5.23761 5.56932 1.78008 0.581879 0.780886
p 0.502004 0.697404 0.234832 0.0724139 0.371397 1 0.571164 0.812829 0.917315 0.0728898 0.0617501 0.410639 0.747561 0.676757
dσ -0.0678469 -0.0177358 0.0291309 -0.0443976 -0.041829 NaN 0.195701 -0.092555 0.114359 0.828592 -0.005510 -11.4573 -2.40962 203.070
k 50 50 50 50 21 0 218 218 218 218 10331 10331 10331 10331
m 50 50 50 50 21 0 49 49 49 49 50 50 50 50
control_m 25 25 25 25 11 0 24 24 24 24 25 25 25 25
intervention_m 25 25 25 25 10 0 25 25 25 25 25 25 25 25
It worsens productivity and creativity (though not quite statistically significantly, but it's on the way there), but at least it improves my mood somewhat (though those results, besides contentment, might as well be due to random chance). No clear effect sizes with the flashcards either.
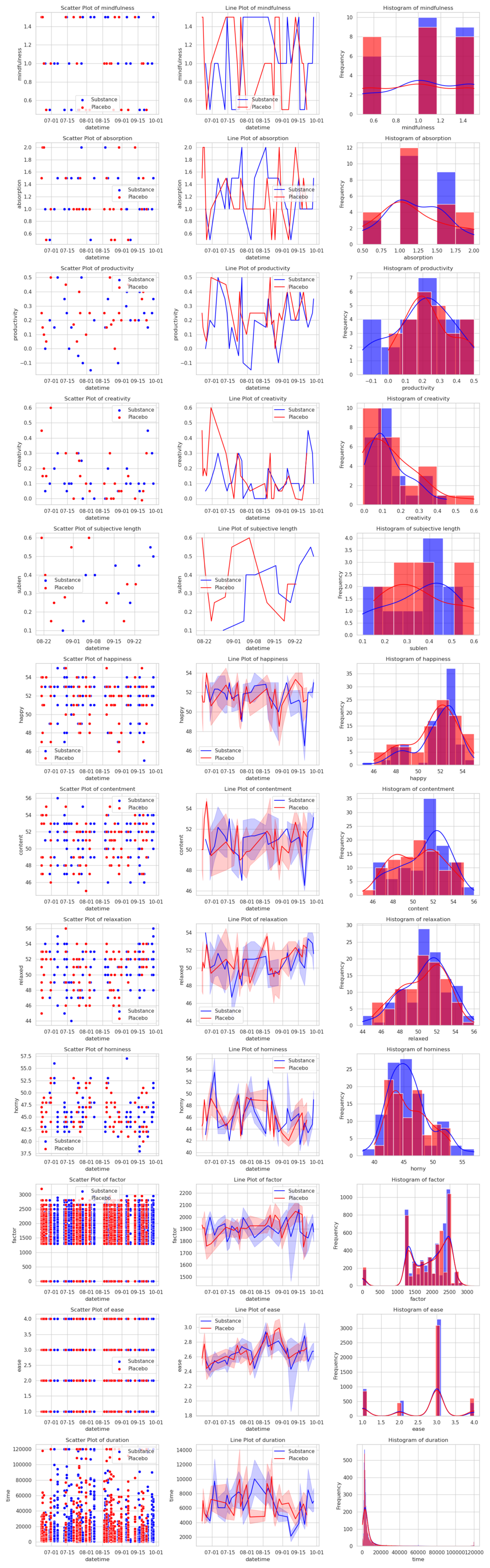
So a hard pass on L-theanine. My current best guess is that as a night owl in the morning I'm still quite tired, and lack energy, with l-theanine just making me more sleepy than I already am. But then again, under Bonferroni correction none of the p-values are statistically significant, so it looks like l-theanine just doesn't do anything. Maybe it's better when combined with caffeine?
After being bullied into it by Gwern 2019 and reading more about dosage & administration in Scott Alexander 2018, I decided to tackle my irregular sleeping rhythm and my late bedtimes by taking Melatonin.
Getting enough high-quality sleep had been quite a problem for most of my life, I just could not find the willpower to actually go to bed early on most days. Most other advice relied on exactly bringing up this willpower (just read before going to bed/just stay away from screens/just do sports in the morning/just spend more time outside/just masturbate (actually counter-productive in my case!)); Gwern's framing as an enforcement mechanism appealed to me, and the cost-benefit analysis seemed sound.
I first tried buying Melatonin at a pharmacy, only to find out that it is prescription only in my country. A friend told me he had bought his from Ebay as a food supplement (laws have interesting loopholes), I ordered 100 3mg pills for ~30€ and they arrived, together with around 10g of protein powder.
I experimented around with administration time & dosage, finding out that 1/8th (≈0.375g) of a pill, administered at ~20:00, was usually sufficient to make me sleepy enough at 23:00 to actually go to bed (though the pills are kind of hard to cut well). I also realized that it was not necessary to take Melatonin every evening, once a good rhythm had been established, a dosage every 2 or 3 days was usually enough to keep the habit of going to bed early.
In the last couple of weeks I've felt like 1/8th of a pill is not enough, perhaps this is adaption to the substance (though I remember reading that adaption is negligible). Alternatively, the placebo effect might be wearing off.
While I haven't experienced more vivid dreams from Melatonin (which I'd consider an advantage), sometimes my sleep on Melatonin is very light, bordering on dozing, and I also sometimes experience sleep paralysis while on melatonin. This is in stark contrast with my normal sleep on melatonin, which I'd guess is deeper than my normal sleep.
One large (potential) advantage of Melatonin would be a reduction in the
amount of time slept.
2½ months after getting a wearable tracker, I decided to analyze
my data on this. I'll spare you the details of data conversion (and
will just say that it's kind of annoying that pandas merge doesn't
implement the antijoin)
and cut straight to the chase (of which the code can be found
here):
>>> melatonin_sleep['minutes_asleep'].mean()
419.72
>>> non_melatonin_sleep['minutes_asleep'].mean()
384.54
>>> non_melatonin_sleep['minutes_asleep'].var()
12966.09
>>> melatonin_sleep['minutes_asleep'].var()
8667.10
>>> len(non_melatonin_sleep)
665
>>> len(melatonin_sleep)
225
It doesn't look like Melatonin has a large effect on sleep durations, at least with the current (meagre) sample sizes).
Maybe it helps if we filter out sleep that starts later than 6:00 in the morning (which excludes naps)?
>>> non_nap_melatonin_sleep=melatonin_sleep.loc[melatonin_sleep['start_time'].dt.hour<6]
>>> non_nap_melatonin_sleep['minutes_asleep'].mean()
419.42
>>> non_nap_non_melatonin_sleep=non_melatonin_sleep.loc[non_melatonin_sleep['start_time'].dt.hour<6]
>>> non_nap_non_melatonin_sleep['minutes_asleep'].mean()
410.02
>>> len(non_nap_melatonin_sleep)
191
>>> len(non_nap_non_melatonin_sleep)
548
>>> lr=control_likelihood_ratio_statistic(non_nap_melatonin_sleep['minutes_asleep'], non_nap_non_melatonin_sleep['minutes_asleep'])
2.2946
>>> llrt_pval(lr)
0.3175
Here it looks like there is a medium-sized advantage to taking melatonin, with ~25 minutes shorter sleep (at the edge of 'statistical significance').
While Melatonin has been very useful at enforcing bedtimes, the advantage of sleeping less has been moderate, and potentially just caused by noise.
I am very glad that I've bought & tried Melatonin; it has to a large degree fixed a significant problem in my life. I am now happier in the morning when I wake up, less tired during the course of the day, and don't have to feel guilty at 04:00 because I stayed up too late.
At my current usage, my stash will last me : more than 4 years! Even if the future effects are just half as good as the past effects, this investment was completely worth it.
I started taking nicotine (in the form of nicotine chewing gum with 2mg of active ingredient) in high-pressure situations (e.g. I'm procrastinating on an important task and have anxiety around it, or during exams). So far, it seems especially useful to break me out of an akratic rut.
See here.
Vitamin D₃ just seems good in general (Wikipedia, Examine, Gwern) and potentially increases longevity.
After ingestion I wait for ~30 minutes, and then start meditating for 30 minutes—15 minutes absorption on the breath, 15 minutes bodyscanning.
Started 2024-08-29, last sample on 2025-04-11.
Notes on the experiment:
I love re-using my code. The analysis this time is very short, I just run the following code (load.py here):
$ python3 -i load.py
>>> vitamind3_datasets=get_datasets('C', 'vitamind3', 'sugar')
>>> analyze(vitamind3_datasets)
absorption mindfulness productivity creativity sublen meaning happy content relaxed horny ease factor ivl time
d -0.0410188 -0.106815 0.0423876 -0.267825 -0.079911 NaN 0.003390 0.184413 -0.212653 -0.193891 -0.005908 -0.010716 0.056719 0.080884
λ 8.35189 0.352702 0.754088 3.26608 20.6711 0 3.29342 1.9815 4.84685 9.41677 0 2.58261 7.21489 5.01076
p 0.0153607 0.838324 0.685886 0.195334 3.246e-05 1 0.192683 0.371297 0.0886178 0.00901934 1 0.274912 0.027121 0.081645
dσ -0.180537 -0.005583 0.0185148 -0.0160734 0.056581 NaN -0.431789 0.227303 0.409001 0.795706 0.003216 -44.108 23.1829 911.813
k 50 50 50 50 50 0 173 173 173 173 1690 1690 1690 1690
m 49 49 49 49 49 0 48 48 48 48 48 48 48 48
control_m 24 24 24 24 24 0 23 23 23 23 23 23 23 23
intervention_m 25 25 25 25 25 0 25 25 25 25 25 25 25 25
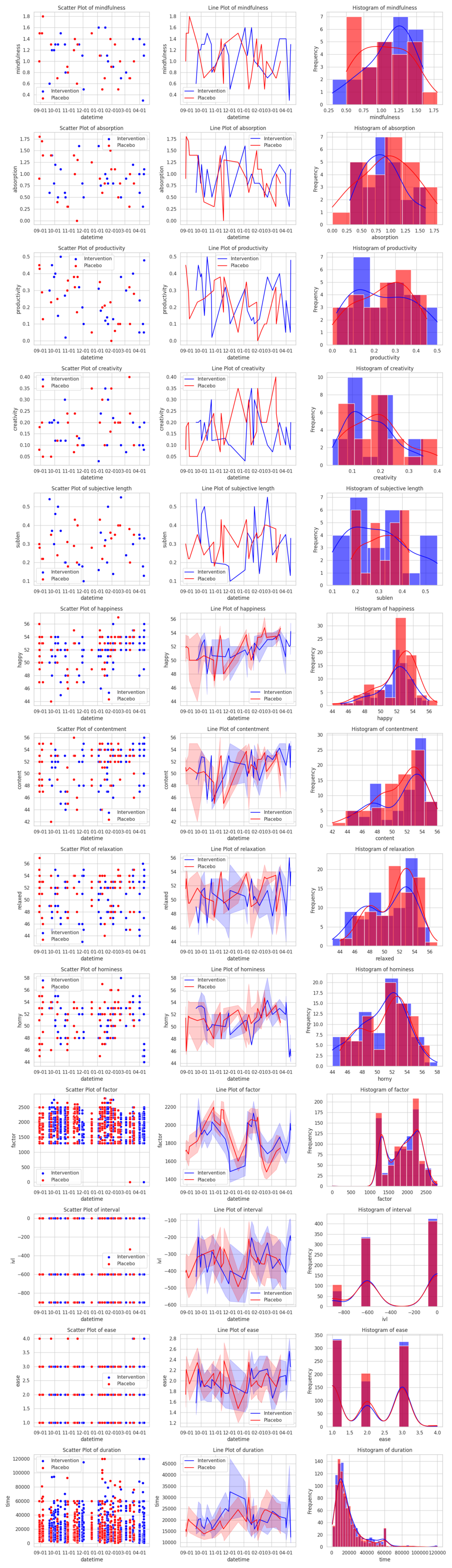
I'd shelve this as a null-to-negative result; meditative absorption is plausibly decreased, subjective length of day is also decreased (but the variance is increased by a lot, if you want to gamble with your subjective length of day take Vitamin D₃), relaxation is slightly decreased as well… for me Vitamin D₃ is probably not worth it.
I'll at some point look at my sleep data for the following night and see whether I can replicate Gwern's results. Too bad, now I have to figure out how these effects trade off against the longevity benefits, my best guess is that further experimentation would show the effect sizes converge towards zero.
At least I fared well in predicting the content of the pills, right?, Right‽
>>> probs=np.array(expc['prediction'])
>>> substances=np.array(expc['substance'])
>>> outcomes=np.array([0 if i=='sugar' else 1 for i in substances])
>>> np.mean(list(map(lambda x: math.log(x[0]) if x[1]==1 else math.log(1-x[0]), zip(probs, out
-0.7072507821345512
God damnit, worse than chance again.
Predicting the outcomes of personal experiments give a useful way to train ones own calibration, I take it a step further and record the predictions for the world to observe my idiocy. The probabilities link to PredictionBook/Fatebook.
| Question | Caffeine probability | Caffeine outcome | L-Theanine probability | L-Theanine outcome | Vitamin D₃ probability | Vitamin D₃ outcome |
|---|---|---|---|---|---|---|
| Prediction of Arm | ||||||
| My prediction about the content of the pill is more accurate than random guesses | 80% | Yes | 65% | No | 50% | No |
| My prediction about the content of the pill has a log score of more than -0.5 | 60% | No | 40% | No | 30% | No |
| Meditation | ||||||
| On intervention days, my average absorption during meditation was higher on placebo days | 40% | No | 55% | Yes | 55% | No |
| On intervention days, my average mindfulness during meditation was higher on placebo days | 60% | Yes | 45% | Yes | 55% | Yes |
| On intervention days, the variance of values for mindfulness during meditation was lower than on placebo days | 55% | No | 60% | No | 45% | Yes |
| On intervention days, the variance of values for absorption during meditation was lower than on placebo days | 35% | Yes | 65% | No | 45% | Yes |
| for absorption values | 25% | No | 5% | No | 40% | No |
| for mindfulness values | 20% | No | 7% | Yes | 40% | Yes |
| for absorption values | 88% | No | 20% | Yes | 70% | No |
| for mindfulness values | 82% | No | 15% | Yes | 70% | Yes |
| for absorption values | 60% | Yes | 95% | Yes | ||
| for mindfulness values | 65% | Yes | 95% | Yes | ||
| Mood | ||||||
| On intervention days, my average happiness was higher on placebo days | 65% | Yes | 55% | Yes | 55% | No |
| On intervention days, my average contentment was higher on placebo days | 45% | Yes | 60% | Yes | 55% | Yes |
| On intervention days, my average relaxation was higher on placebo days | 35% | No | 65% | Yes | 52% | No |
| On intervention days, my average horniness was higher on placebo days | 50% | No | 50% | No | 50% | No |
| On intervention days, the variance of values for happiness was lower than on placebo days | 55% | No | 60% | Yes | 45% | Yes |
| On intervention days, the variance of values for contentment was lower than on placebo days | 30% | No | 65% | Yes | 45% | No |
| On intervention days, the variance of values for relaxation was lower than on placebo days | 30% | No | 65% | No | 45% | No |
| On intervention days, the variance of values for horniness was lower than on placebo days | 50% | No | 50% | No | 48% | No |
| for happiness values | 45% | No | 8% | No | 10% | No |
| for contentment values | 40% | No | 5% | No | 12% | Yes |
| for relaxation values | 37% | No | 5% | No | 15% | No |
| for chastity values | 60% | No | 10% | No | 18% | No |
| for happiness values | 85% | No | 18% | No | 45% | Yes |
| for contentment values | 90% | No | 12% | No | 50% | Yes |
| for relaxation values | 90% | No | 12% | Yes | 40% | No |
| for chastity values | 95% | Yes | 20% | Yes | 55% | Yes |
| for happiness values | 75% | Yes | 90% | Yes | ||
| for contentment values | 70% | Yes | 95% | Yes | ||
| for relaxation values | 70% | Yes | 95% | Yes | ||
| for chastity values | 85% | Yes | 95% | Yes | ||
| Productivity and Creativity | ||||||
| On intervention days, my average productivity was higher on placebo days | 52% | Yes | 65% | No | 55% | Yes |
| On intervention days, my average creativity was higher on placebo days | 55% | Yes | 55% | No | 52% | No |
| On intervention days, the variance of values for productivity was lower than on placebo days | 40% | No | 70% | No | 40% | No |
| On intervention days, the variance of values for creativity was lower than on placebo days | 65% | No | 50% | Yes | 45% | Yes |
| for productivity values | 40% | No | 7% | No | 5% | Yes |
| for creativity values | 45% | No | 9% | No | 7% | No |
| for productivity values | 75% | No | 20% | No | 20% | Yes |
| for creativity values | 80% | No | 25% | No | 25% | Yes |
| for productivity values | 60% | Yes | 70% | Yes | ||
| for creativity values | 70% | Yes | 75% | Yes | ||
| Subjective length | ||||||
| The average subjective length of intervention days was higher placebo days | 60% | No | ||||
| The average variance of subjective length of intervention days was higher than placebo days | 60% | No | ||||
| for subjective length values | 4% | No | ||||
| for subjective length values | 22% | No | ||||
| for subjective length values | 75% | No |
I also recorded my predictions about the content of the pill on PredictionBook/Fatebook:
I continue to be worse than chance in my predictions on the outcomes of my own experiments:
>>> import math
>>> import numpy as np
>>> probs=np.array([0.8, 0.6, 0.6, 0.4, 0.55, 0.35, 0.2, 0.25, 0.82, 0.88, 0.65, 0.45, 0.35, 0.5, 0.55, 0.3, 0.3, 0.5, 0.45, 0.4, 0.37, 0.6, 0.85, 0.9, 0.9, 0.95, 0.52, 0.55, 0.4, 0.65, 0.4, 0.45, 0.75, 0.8])
>>> outcomes=np.array([1, 0, 1, 1, 0, 1, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 1, 1, 0, 1, 1, 0, 0, 0, 0, 0, 0])
>>> np.mean(list(map(lambda x: math.log(x[0]) if x[1]==1 else math.log(1-x[0]), zip(probs, outcomes))))
-0.8460012842154898
>>> np.mean(list(map(lambda x: math.log(x[0]) if x[1]==1 else math.log(1-x[0]), zip([0.5]*50, outcomes))))
-0.6931471805599452
Die Welt gibt dir viel falsche Zeichen,
dem tückischen Geist zu vergleichen,
Du bist, alle Zeichen verachtend,
zu dem ohne Zeichen gegangen.
—Dschelāladdīn Rūmī, “Am Ende bist du entschwunden”, 1256
| Value tracked | Effect size d (λ, p, σ change, k6) | Effect size d (λ, p, σ change, k) | Effect size d (λ, p, σ change, k) |
|---|---|---|---|
| 200 mg Caffeine (n=1, m=50) | 500 mg L-theanine (n=1, m=50) | 25μg Vitamin D₃ (n=1, m=50) | |
| Log-score of prediction | -0.6 | -0.7 | -0.707 |
| Absorption | 0.70 (λ≈13.3, p≈0.0013, -0.072, 50) | 0.05 (λ≈1.38, p≈0.50, -0.068, 50) | -0.04 (λ≈8.35, p≈0.015, -0.181, 50) |
| Mindfulness | 0.64 (λ≈11.8, p≈0.0028, 0.022, 50) | 0.15 (λ≈0.72, p≈0.70, -0.018, 50) | -0.11 (λ≈0.35, p≈0.84, -0.006, 50) |
| Productivity | 0.64 (λ≈30.8, p≈2.1e-7, 0.107, 50) | -0.21 (λ≈2.90, p≈0.23, 0.029, 50) | 0.04 (λ≈0.75, p≈0.69, 0.019, 50) |
| Creativity | 0.51 (λ≈56.3, p≈5.8e-13, 0.098, 50) | -0.10 (λ≈5.25, p≈0.072, -0.044, 50) | -0.27 (λ≈3.27, p≈0.20, -0.016, 50) |
| Subjective duration | Not collected | 0.12 (λ≈1.98, p≈0.37, -0.042, 21) | -0.08 (λ≈20.7, p≈3.2e-5, 0.057, 50) |
| Happiness | 0.26 (λ≈10.9, p≈0.0044, 0.304, 180) | 0.03 (λ≈1.12, p≈0.57, 0.196, 218) | 0.003 (λ≈3.29, p≈0.19, -0.432, 173) |
| Contentment | 0.09 (λ≈0.64, p≈0.73, 0.112, 180) | -0.03 (λ≈0.41, p≈0.81, -0.093, 218) | 0.18 (λ≈1.98, p≈0.37, 0.227, 173) |
| Relaxation | -0.02 (λ≈0.19, p≈0.91, 0.154, 180) | -0.01 (λ≈0.17, p≈0.92, 0.114, 218) | -0.21 (λ≈4.85, p≈0.089, 0.409, 173) |
| Horniness | -0.07 (λ≈1.11, p≈0.57, 0.360, 180) | -0.01 (λ≈5.24, p≈0.073, 0.829, 218) | -0.19 (λ≈9.42, p≈0.009, 0.796, 173) |
| Flashcard ease | -0.012 (λ≈2.98, p≈0.23, -0.026, 10953) | -0.073 (λ≈5.57, p≈0.062, -0.006, 10331) | -0.006 (λ≈0, p≈1, 0.003, 1690) |
| Flashcard ease factor | 0.001 (λ≈7.42, p≈0.024, -30.9, 10953) | -0.017 (λ≈1.78, p≈0.41, -11.5, 10331) | -0.011 (λ≈2.58, p≈0.27, -44.1, 1690) |
| Flashcard new interval | 0.025 (λ≈4.17, p≈0.12, -5.26, 10953) | -0.011 (λ≈0.58, p≈0.75, -2.41, 10331) | 0.057 (λ≈7.21, p≈0.027, 23.2, 1690) |
| Time per flashcard | -0.003 (λ≈4.07, p≈0.13, -651, 10953) | -0.017 (λ≈0.78, p≈0.68, 203, 10331) | 0.081 (λ≈5.01, p≈0.082, 912, 1690) |
The number of participants. Usually only one, me. ↩
The number of days during which samples were collected. ↩
Higher is better. ↩
Whether higher or lower values are better here is not clear. ↩
The value of higher or lower values here is not clear: Do we want to spend more time per flashcard, or are we content with fast but sloppy performance? ↩
The number of datapoints for that variable. Can be greater than the number of days since for some variables more than one a day were collected. ↩