author: niplav, created: 2023-01-04, modified: 2026-03-31, language: english, status: in progress, importance: 7, confidence: certain
There are too many possible quantified self experiments to run. Do hobbyist prediction platforms1 make priorisation easier? I test this by setting up multiple markets, in order to run two experiments (the best one, and a random one), mostly for the effects of various nootropics on absorption in meditation. The first experiment (testing the Pomodoro method) results in a log score of -0.326 for the market, the second experiment (testing Vitamin D₃) results in a log score of -0.333 — pretty good.
The scores provide ~1.08 bits of evidence for the efficacy of futarchy.
dynomight 2022 has a very cool proposal:
Oh, and by the way are you THE NSF or DARPA or THE NIH or A BILLIONAIRE WHO WANTS TO SPEND LOTS OF MONEY AND BRAG ABOUT HOW YOU ADVANCED THE STATE OF HUMAN KNOWLEDGE MORE THAN ALL THOSE OTHER LAME BILLIONAIRES WHO WOULDN’T KNOW A HIGH ROI IF IT HIT THEM IN THE FACE? Well how about this:
- Gather proposals for a hundred RCTs that would each be really expensive but also really awesome. (E.g. you could investigate
SALT → MORTALITYorALCOHOL → MORTALITYorUBI → HUMAN FLOURISHING.)- Fund highly liquid markets to predict the outcome of each of these RCTs, conditional on them being funded.
- If you have hangups about prison, you might want to chat with the CFTC before doing this.
- Randomly pick 5% of the proposed projects, fund them as written, and pay off the investors who correctly predicted what would happen.
- Take the other 95% of the proposed projects, give the investors their money back, and use the SWEET PREDICTIVE KNOWLEDGE to pick another 10% of the RCTs to fund for STAGGERING SCIENTIFIC PROGRESS and MAXIMAL STATUS ENHANCEMENT.
—dynomight, “Prediction market does not imply causation”, 2022
Well, I'm neither a billionaire nor the NSF or DARPA, but I have run two shitty self-blinded RCTs on myself already, and I'm certainly not afraid of the CFTC. And indeed I don't have a shortage of ideas on things I could run RCTs on, but the time is scarce (I try to collect m=50 samples in each RCT, which (with buffer-days off) is usually more than 2 months of data collection).
So I'll do what @saulmunn pointed out to me is a possibility: I'm going to do futarchy (on) myself by setting up a set of markets of Manifold Markets with respect to the outcomes of some pre-specified self-blinded RCTs, waiting until the prices on them equilibriate, and then running two of those RCTs (the "best" one, by my standards, and a random one) and using the results as resolutions, while resolving the others as ambiguous.
I started the first experiment early in 2024, and the second experiment in late 2024, finishing the second one in early 2025. The third experiment on lumenators was finished in early 2026.
Some experiments can be self-blinded, especially ones that involve substances, others can not because they require me to engage in an activity or receive some sensory input, so I distinguish the two, and will slightly prioritise the experiments that can be blinded.
In all experiments, I will be using the statistical method detailed here, code for it here, unless someone points out that I'm doing my statistics wrong.
I will be scoring the markets based on the variables specified in the prediction market title, but I'll of course be collecting a lot of other data during that time that will also be analyzed.
| Experiment | Number of Traders | Trading Volume | Expected Effect Size | Resolved Effect Size |
|---|---|---|---|---|
| L-Theanine + Caffeine vs. Sugar → Meditative Absorption | 14 | M̶515 | 0.306 | |
| Nicotine vs. Normal chewing gum → Meditative Absorption | 7 | M̶342 | 0.437 | |
| Modafinil vs. Sugar → Meditative Absorption | 11 | M̶668 | 0.337 | |
| Vitamin D vs. Sugar → Meditative Absorption | 11 | M̶675 | 0.169 | -0.14 |
| Vitamin B12 vs. Sugar → Meditative Absorption | 7 | M̶303 | 0.182 | |
| LSD Microdosing vs. Water → Meditative Absorption | 6 | M̶174 | 0.286 | |
| CBD Oil vs. Similar-Tasting Oil → Meditative Absorption | 9 | M̶210 | 0.227 | |
| L-Phenylalanine vs. Sugar → Meditative Absorption | 7 | M̶269 | 0.302 | |
| Bupropion vs. Sugar → Happiness | 8 | M̶303 | 0.337 | |
| THC Oil vs. Similar-Tasting Oil → Meditative Absorption | 10 | M̶230 | 0.344 | |
| Intermittent Fasting vs. Normal Diet → Happiness | 13 | M̶228 | 0.348 | |
| Pomodoro Method vs. Nothing → Productivity | 9 | M̶300 | 0.397 | 0.26 |
| Bright Light vs. Normal Light → Happiness | 9 | M̶104 | 0.473 | 0.55 |
| Meditation vs. No Meditation → Sleep duration | 13 | M̶380 | 0.241 |
In general, by meditative absorption I mean the concentration/tranquility (in Buddhist terms samatha) during a ≥30 minute meditation session in the morning, ~45 minutes after waking up and taking the substance (less if the substance starts working immediately). I will be doing at least 15 minutes of anapanasati during that meditation session, but might start (or end) with another practice).
Past meditation data can be found here.
0.06*1+0.14*0.8+0.26*0.4+0.3*0.1+0.2*0=0.3060.1*1+0.25*0.8+0.28*0.4+0.25*0.1+0.11*0=0.4370.03*1+0.2*0.8+0.29*0.4+0.31*0.1+0.18*0=0.3370.04*1+0.06*0.8+0.1*0.4+0.41*0.1+0.38*0=0.1690.03*1+0.09*0.8+0.1*0.4+0.4*0.1+0.38*0=0.1820.06*1+0.14*0.8+0.21*0.4+0.3*0.1+0.29*0=0.2860.04*1+0.1*0.8+0.18*0.4+0.35*0.1+0.35*0=0.2270.06*1+0.16*0.8+0.2*0.4+0.34*0.1+0.23*0=0.3020.05*1+0.19*0.8+0.27*0.4+0.27*0.1+0.22*0=0.3370.07*1+0.18*0.8+0.27*0.4+0.22*0.1+0.26*0=0.344Some experiments can't be blinded, but they can still be randomized. I will focus on experiments that can be blinded, but don't want to exclude the wider space of interventions.
echo -e "fast\ndon't fast" | shuf | tail -1. Expected duration of the trial: ~2 months.
0.03*1+0.18*0.8+0.36*0.4+0.3*0.1+0.13*0=0.348echo -e "pomodoro\nno pomodoro" | shuf | tail -1. Expected duration of trial: 2 months.
0.07*1+0.19*0.8+0.39*0.4+0.29*0.1+0.06*0=0.397echo -e "lamp\nno lamp" | shuf | tail -1. Expected duration of trial: 4 months, as I often don't spend all my day at home.
0.11*1+0.29*0.8+0.27*0.4+0.23*0.1+0.1*0=0.473echo -e "meditation\nno meditation" | shuf | tail -1. Expected duration of trial: 5 months, as I might not always find a 2-day interval in which I'm sure I can meditative 2h/day.
0.04*1+0.08*0.8+0.21*0.4+0.53*0.1+0.15*0=0.241This little exercise may need your participation! I have three pleas to you, dear reader:
Other than that, I also welcome all critiques at any level of detail of this undertaking.
If I could create more markets, I might be able to put up markets on different variables I measure during the day. That way, I could select interventions that dominate others across multiple dimensions.
If there were prediction platforms that supported them, combinatorial prediction markets or latent-variable prediction markets could be incredibly cool, but we don't live in that world (yet).
On 2024-01-25, I decided to select the experiment.
seq 1 14 | shuf | tail -1 output 12, which corresponds
to the experiment Pomodoro Method vs. Nothing →
Productivity.
The market with the highest expected effect size is Bright Light vs. Normal Light → Happiness, so those are the two experiments I am going to run.
I am a bit weary of selecting these two markets: The Bright Light market has the lowest trading volume of all markets, at only M̶104, and both these markets are not blindeable.
But a commitment I have made, so a commitment I have to follow through with.
| Value tracked | d | λ | p | σ change | k |
|---|---|---|---|---|---|
| Pomodoro method (n=1) | |||||
| Productivity | 0.27 | 4.62 | 0.099 | -0.041 | 54 |
| Creativity | -0.18 | 0.95 | 0.623 | 0.008 | 54 |
| Subjective length | -0.08 | 4.01 | 0.135 | 0.041 | 54 |
| Happiness | 0.006 | 0.98 | 0.612 | -0.197 | 111 |
| Contentment | -0.10 | 1.92 | 0.382 | -0.282 | 111 |
| Relaxation | -0.09 | 2.45 | 0.294 | -0.370 | 111 |
| Horniness | -0.26 | 2.94 | 0.230 | 0.495 | 111 |
Hue indicates effect size, opacity indicates likelihood ratio (higher opacity = higher λ).
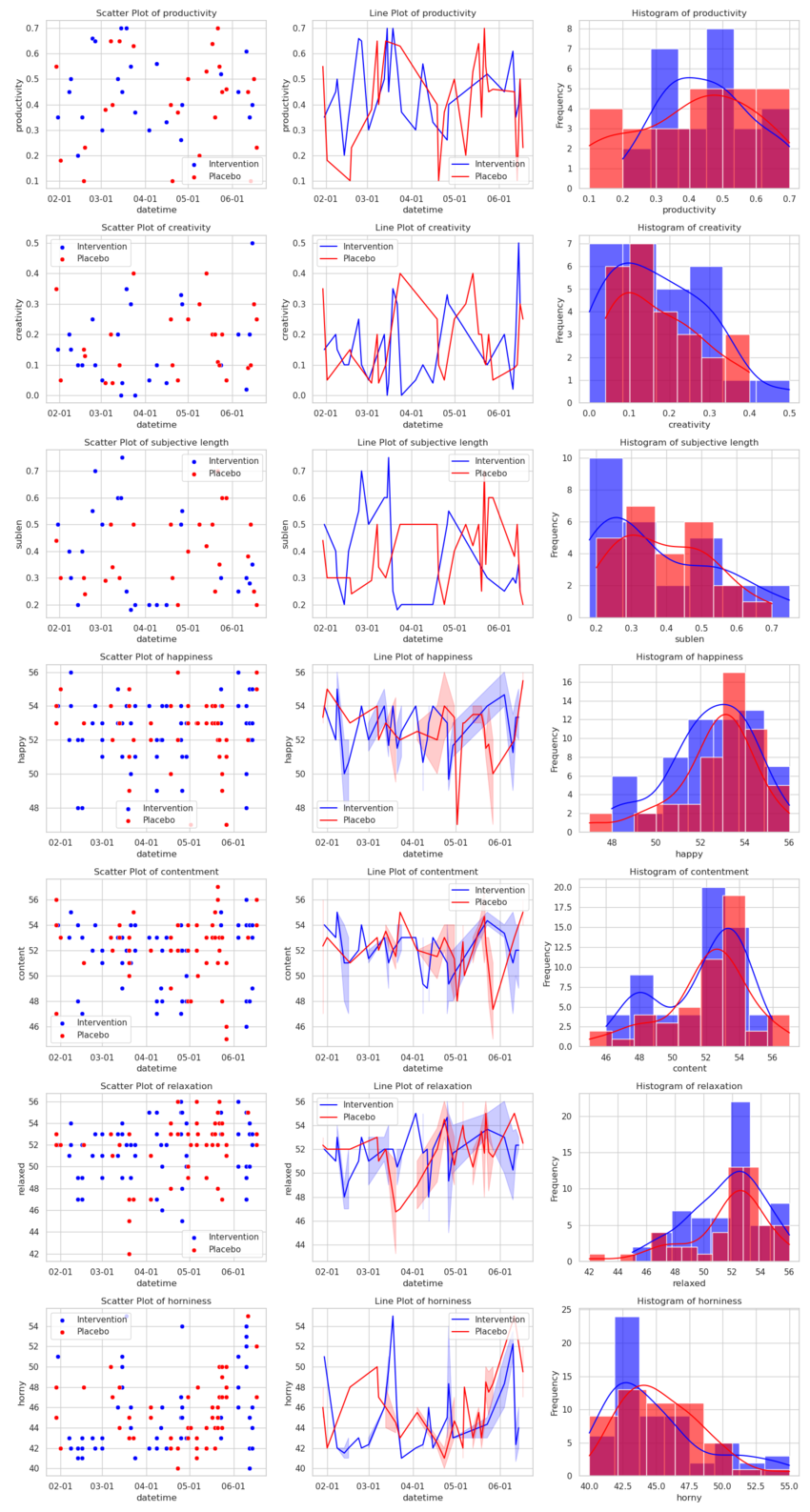
I ran the experiment from 2024-01-29 to 2024-06-17, using spt with this script, managed by this script.
The data on whether a particular day was a pomodoro-method day was saved in this file, and the data on the pomodoros was saved in this file.
The code for loading and transforming the pomodoro data isn't particularly interesting, if you're curious you can find it in this file.
datasets=get_datasets_pom()
Let's proceed to the analysis, then (using the same methodology as for my nootropics experiments:
res=analyze(datasets)
And the results are:
>>> pd.set_option('display.float_format', '{:.4f}'.format)
>>> res
productivity creativity sublen happy content relaxed horny ease factor ivl time
d 0.2578 -0.1303 -0.1401 -0.0737 -0.1328 -0.0383 -0.1440 0.3762 0.0316 -0.1460 -0.7109
λ 5.4134 0.5083 4.0581 0.3189 1.0785 1.2329 7.7563 7.9529 2.1974 1.3936 41.8069
p 0.1172 0.9307 0.2563 0.9596 0.8272 0.7960 0.0229 0.0197 0.5897 0.7625 0.0000
dσ -0.0442 0.0061 0.0375 0.0072 0.0477 -0.2524 0.7447 -0.0700 165.3438 17.9768 -4738.1968
k 54.0000 54.0000 54.0000 111.0000 111.0000 111.0000 111.0000 116.0000 116.0000 116.0000 116.0000
control_k 27.0000 27.0000 27.0000 51.0000 51.0000 51.0000 51.0000 65.0000 65.0000 65.0000 65.0000
intervention_k 27.0000 27.0000 27.0000 60.0000 60.0000 60.0000 60.0000 51.0000 51.0000 51.0000 51.0000
m 51.0000 51.0000 51.0000 50.0000 50.0000 50.0000 50.0000 2.0000 2.0000 2.0000 2.0000
control_m 27.0000 27.0000 27.0000 24.0000 24.0000 24.0000 24.0000 1.0000 1.0000 1.0000 1.0000
intervention_m 25.0000 25.0000 25.0000 26.0000 26.0000 26.0000 26.0000 1.0000 1.0000 1.0000 1.0000
I don't know why the daycounts for productivity don't add up, something fishy is going on in my data analysis—possibly a day with duplicated data. I didn't meditate and mostly didn't do flashcards during that time.
So the pomodoro method somewhat increases productivity (at the edge of statistical significance), and maybe decreases subjective length of the day a bit. It also decreases horniness a little bit, which I find pretty funny2.
The lumenator RCT ran from 2024-07-02 until 2026-02-19, using twenty 6000K HZSANUE bulbs and four 3500K HZSANUE bulbs (following the advice in Korzekwa 2020).
At 1350 lm each this resulted in 32400 lm total, at CRI >85 (not great but I don't have a huge problem with it). I hung up the bulbs on a string light around & above my desk facing so that the light was distributed evenly at a distance of 1–2m, in winter that resulted in my room being noticeably brighter than the outside, and probably made it look like a supervillain's den. I didn't measure the lux at my desk.
I tracked my standard variables, though was slightly inconsistent with some of them, especially flashcard results are to be taken with a large grain of salt.
| Value tracked | d | λ | p | σ change | k |
|---|---|---|---|---|---|
| Lumenator ~30k lumen (n=1) | |||||
| Absorption | -0.4451 | 3.09 | 0.410 | -0.027 | 32 |
| Mindfulness | -0.7275 | 9.09 | 0.008 | -0.087 | 32 |
| Productivity | 0.2087 | 2.50 | 0.527 | 0.023 | 50 |
| Creativity | 0.0140 | 0.57 | 0.921 | 0.014 | 50 |
| Subjective duration | 0.5061 | 10.28 | 0.003 | 0.031 | 50 |
| Meaning | 0.0358 | 0.140 | 0.984 | 0.02 | 22 |
| Happiness | 0.679 | 31.23 | 1.7e-7 | -0.745 | 198 |
| Contentment | 0.501 | 16.30 | 2.9e-4 | -0.231 | 198 |
| Relaxation | 0.499 | 28.08 | 8.0e-7 | 0.144 | 198 |
| Horniness | 0.300 | 4.55 | 0.103 | -0.571 | 198 |
| Flashcard ease | 0.023 | 0 | 1 | 0.026 | 295 |
| Flashcard ease factor | 0.400 | 3.42 | 0.181 | 52.481 | 295 |
| Flashcard new interval | -0.071 | 2.74 | 0.254 | 30.769 | 295 |
| Time per flashcard | -0.050 | 2.77 | 0.250 | -930.400 | 295 |
Hue indicates effect size, opacity indicates likelihood ratio (higher opacity = higher λ).
Most stark are the results on multiple subjective values, especlly happiness which is the most commonly-talked-about endpoint, yielding d≥0.5 in improvement. Improvements in contentment & relaxation similarly are pleasant surprises, though these are pretty correlated in my dataset and come apart only when taking caffeine. The slight increase in horniness is probably correlated with a feeling of "vitality", but it's not a huge effect and can probably be ignored.
End-of-day metrics like the retrospective subjective length of the day being increased is also pretty cool, and I'm surprised retrospective meaning didn't get affected at all (perhaps due to only being measured half of all the days because I started collecting it only mid 2025).
A big surprise is the lack of a statistically significant increase in productivity, it's a metric people commonly report as having increased after getting their lumenator. (Productivity assessment over the day is somewhat hazardous, I could cross-check with my number of hours worked, though I have a smaller sample size for that.)
The meditation results are curious, I don't know what exactly to make of them. Mindfulness having such a large decrease feels confusing (absorption isn't really statistically significant but still worth keeping an eye out for).
Flashcard data is a wash due to a small number of days on which I actually did flashcards (nine days in total), the effect size is likely due to pseudoreplication.
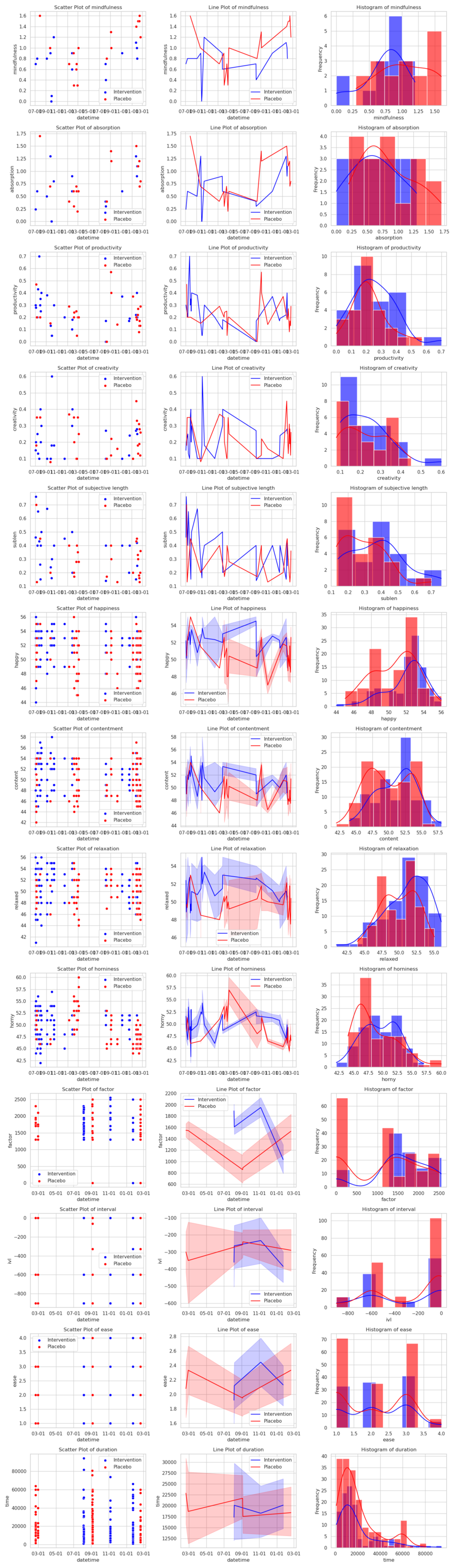
~/proj/site/code/experiments » python3 -i load.py
>>> pd.set_option('display.float_format', '{:.4f}'.format)
>>> datasets=get_datasets_light()
>>> res=analyze(datasets)
>>> res
absorption mindfulness productivity creativity sublen meaning happy content relaxed horny ease factor ivl time
d -0.4451 -0.7275 0.2087 0.0140 0.5061 0.0358 0.5518 0.3823 0.4046 0.2238 0.1079 0.5192 -0.1511 -0.0449
λ 3.0944 9.0917 2.4987 0.5691 10.2831 0.1403 31.0045 15.6398 28.3924 7.6674 2.5491 43.8971 4.6378 0.4189
p 0.4101 0.0079 0.5265 0.9208 0.0029 0.9835 0.0000 0.0000 0.0000 0.0245 0.5161 0.0000 0.1864 0.9447
dσ -0.0269 -0.0866 0.0233 0.0144 0.0310 0.0199 -0.2440 -0.3504 0.5453 -0.4503 -0.0670 -232.2879 29.1267 577.4129
k 32.0000 32.0000 50.0000 50.0000 50.0000 22.0000 198.0000 198.0000 198.0000 198.0000 295.0000 295.0000 295.0000 295.0000
control_k 17.0000 17.0000 25.0000 25.0000 25.0000 14.0000 101.0000 101.0000 101.0000 101.0000 180.0000 180.0000 180.0000 180.0000
intervention_k 15.0000 15.0000 25.0000 25.0000 25.0000 8.0000 97.0000 97.0000 97.0000 97.0000 115.0000 115.0000 115.0000 115.0000
m 32.0000 32.0000 50.0000 50.0000 50.0000 22.0000 50.0000 50.0000 50.0000 50.0000 9.0000 9.0000 9.0000 9.0000
control_m 17.0000 17.0000 25.0000 25.0000 25.0000 14.0000 25.0000 25.0000 25.0000 25.0000 5.0000 5.0000 5.0000 5.0000
intervention_m 15.0000 15.0000 25.0000 25.0000 25.0000 8.0000 25.0000 25.0000 25.0000 25.0000 4.0000 4.0000 4.0000 4.0000
The Vitamin D₃ experiment finished successfully with full data collection, with an effect size of ≈-0.137 of Vitamin D₃ on absorption (more at the link).
I can now score the market with the results from the two experiments:
import numpy as np
def logscore(o,p):
return np.mean(o*np.log(p)+(np.ones_like(o)-o)*np.log(np.ones_like(p)-p))
pomodoro_p=np.array([0.06, 0.29, 0.39, 0.19, 0.07])
pomodoro_o=np.array([0, 0, 1, 0, 0])
logscore(pomodoro_o, pomodoro_p)
-0.3258531953347593
vitamin_p=np.array([0.39, 0.41, 0.08, 0.06, 0.05])
vitamin_o=np.array([1, 0, 0, 0, 0])
logscore(vitamin_o, vitamin_p)
-0.3331583177971012
lumenator_p=np.array([0.11, 0.23, 0.27, 0.29, 0.11])
lumenator_o=np.array([0, 0, 1, 0, 0])
logscore(lumenator_o, lumenator_p)
-0.42925120511536974
Honestly: The markets did pretty well.
So, I put up some prediction markets on the results of quantified self RCTs. I ran two of the experiments, and scored both markets on the results.
How much should the performance of the market change our opinion about the viability of using prediction platforms to predict RCTs, and thus be plausibly useful in selecting experiments to run and actions to perform?
One issue here is that we only observed three datapoints: Three logscores from the markets on the Pomodoro method (-0.326), the Vitamin D₃ experiment (-0.333), and the Lumenator experiment (-0.429). Qualitatively these are already fairly assuring because they're both far better than a random score of -0.69. But if we want to quantify the amount of information we've gained, we can do that by performing a Bayesian update.
For that, we need a prior. What prior to choose? I tried fiddling around a bit with the exponential distribution, which is the maximum entropy distribution over possible logscores, only nailed down by the mean of the distribution. It represents a state of minimal knowledge.
There's also the Gamma distribution which is great because it's a conjugate prior assuming an exponentially distributed underlying data generating process. So, after updating on the datapoints we again get a Gamma-distribution as the posterior.
But I didn't go with that one because… I wasn't getting the pretty results I wanted3.
With the exponential distribution, a thing that happened was that I'd calculate the resulting distribution after two updates, but the first update would be very aggressive and the second update would then update away harder than the first update had updated towards the datapoints, causing a net information loss. The exponential distribution also has very long tails, resulting in a median of -1.0, which implies that the median market has a logscore that is worse than chance. I don't believe that to be the case. (The maxent mean implies that the mean market is only as good as chance, which I also wouldn't believe a priori? I think?)
As for using the Gamma distribution as a prior, I simply don't think that the underlying data generating process is exponentially distributed, and thus we don't get any advantage through conjugacy. The Gamma distribution also has two parameters, which is too much to be nailed down with only two datapoints.
So I decided to pick a different prior, and landed on the half normal
distribution
with half-normally distributed variance (σ ~ HalfNormal(0.5)), which
has some nicer properties than the exponential distribution, especially
with its thin tails. But the half normal distribution can't be updated
in a closed-form solution, so instead I had to write a short script
using pymc. Because of missing
conjugacy the resulting distribution is not a half-normal distribution,
but something a lot more complicated. I can't be bothered to try to
calculate what it even is.
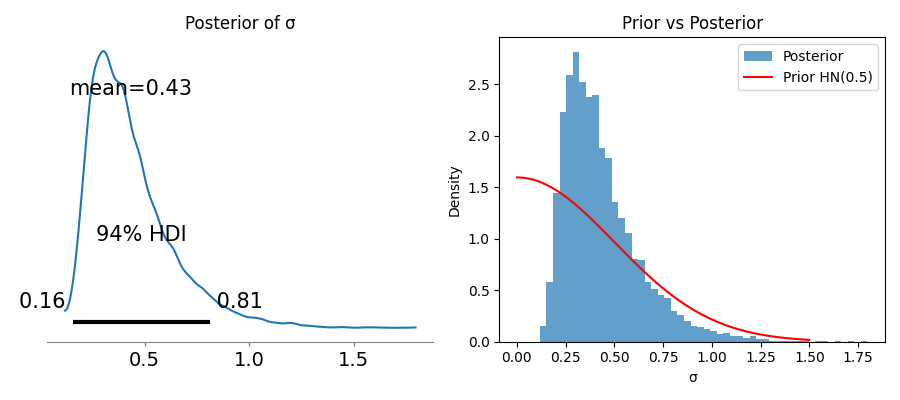
Summary visualization of the update:
The script4 initializes the model with the
half normal prior, which in turn has a standard
deviation distributed
with HalfNormal("sigma", sigma=0.5). We then update on observed=[0.326,
0.333, 0.429]:
with pm.Model() as adaptive_model:
σ = pm.HalfNormal('sigma', sigma=0.5)
obs = pm.HalfNormal('distances', sigma=σ, observed=distances)
trace = pm.sample(2000, tune=1000, chains=4, target_accept=0.95,
return_inferencedata=True)
We can then observe the samples for the new standard deviation
σ_samples = trace.posterior.sigma.values.flatten()
σ_mean = np.mean(σ_samples)
and calculate the log-likelihoods, the Bayes factor, and the number of bits in the update:
results = {}
null_σ = null_sigmas[0]
ll_adaptive = np.sum(stats.halfnorm.logpdf(distances, scale=σ_mean))
ll_null = np.sum(stats.halfnorm.logpdf(distances, scale=null_σ))
log_bf = ll_adaptive - ll_null
bits = log_bf / np.log(2)
bf = np.exp(log_bf)
The whole script has this output:
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 2 jobs)
NUTS: [sigma]
Progress Draws Divergences Step size Grad evals Sampling Speed Elapsed Remaining
─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 3000 0 0.69 1 1165.53 draws/s 0:00:02 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 3000 0 1.12 3 1135.09 draws/s 0:00:02 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 3000 0 0.48 1 600.10 draws/s 0:00:04 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 3000 0 0.78 1 566.57 draws/s 0:00:05 0:00:00
Sampling 4 chains for 1_000 tune and 2_000 draw iterations (4_000 + 8_000 draws total) took 5 seconds.
Posterior summary:
mean sd hdi_3% hdi_97% mcse_mean mcse_sd ess_bulk ess_tail r_hat
sigma 0.449 0.178 0.196 0.786 0.004 0.004 2550.0 2692.0 1.0
Posterior mean σ: 0.449
vs Null σ = 0.7:
Log likelihood (adaptive): 0.730
Log likelihood (null): -0.017
Evidence: 1.08 bits
Bayes factor: 2.1:1 in favor of adaptive
Posterior mean σ: 0.449
95% credible interval: [0.189, 0.812]
Evidence: 1.077 bits
(vs null hypothesis σ = 0.7)
Thus: 1.077 bits in favor of futarchy5.
Many thanks to clippy (twitter) for M̶500, and Tetraspace (twitter) for M̶1000, which I used to subsidize the markets. Also many thanks to the manifold admin Genzy for subsidizing each market with M̶450.
Your funding of the sciences is greatly appreciated.
My gratitude also goes out to all the traders on the markets. You help me prioritize, you help us gain knowledge.
Over time, I'll put some explanations on why these specific experiments interest me. Not yet fully, though.
My l-theanine experiment gave disappointing results, but people have (rightfully) pointed out that l-theanine is best taken together with caffeine: one gets energy and relaxation at the same time.
This points at a broader possibility: Why not set up markets for all possible combinations of nootropics? But alas, this runs into problems with combinatorial explosion.
Vitamin D seems just generally great, so it's not super far out to suspect that supplementing it after waking up could have positive effects on wakefulness.
Inspired by Gwern 2019.
My brother, in conversation, brought up that smoking weed is incredibly relaxing to him, and told me he imagines that this is what he thinks deep meditative states feel like. That intrigues me enough to consider it as intervention towards absorption, if not mindfulness (albeit one that has the danger of creating subtly dull states of mind).
The Pomodoro technique also uses the concept of rhythm, breaking up the day into twenty-five-minute segments of work and five minutes of a break. Interestingly, though, I found no academic study that tested the technique.
—Gloria Mark, “Attention Span” p. 66, 2023
It'd be cool if I were the first person to actually test this widespread technique.
See also:
I have a couple more ideas on possible experiments that I could run, and will put them up as I acquire more mana. I might also just farm highly-rated but rarely-investigated methods from troof 2022 and experiences reported here.
Blindeable:
Not blindeable:
I find it odd to call any platform on which people functionally give probabilities, but without staking real money, "prediction markets". Neither Metaculus not Manifold Markets are prediction markets, but PredictIt and Kalshi are. ↩
p<0.05, after all. (Don't pay any attention to the Bonferroni correction lurking over there, it's not important.) ↩
This is very bad statistical practice. I'm doing this because I want a cutesy title with a positive number of of bits as an update, and because I wanted to learn how to do Bayesian updating using computers. ↩
Code here. Thanks to Claude 4 Sonnet for writing the code and walking me through the process. ↩
Under several favorably cherry-picked assumptions. Don't @ me. ↩