![Text: "paranoia is a profession. And so LeAIthan represents the most advanced ef[line split on ligature here]fort yet in AI alignment, using *factored* cognition—splitting up into a"](./img/pet_peeves/ff_split.png "Image of text: “paranoia is a profession. And so LeAIthan represents the most advanced ef[line split on ligature here]fort yet in AI alignment, using *factored* cognition—splitting up into a”")
author: niplav, created: 2019-05-22, modified: 2026-01-06, language: english, status: in progress, importance: 3, confidence: other
Short texts on different topics.
Das Immer-wieder-von-vorn-anfangen ist die regulative Idee des Spiels (wie der Lohnarbeit).
—Walter Benjamin, “Über einige Motive bei Baudelaire“, 2023, link mine
If something isn't long enough to be its own article (yet…) and it is neither ethics- nor politics-, prediction- or pickup-related, I put it here.
Many people want to learn everything (Drexler 2009, Young 2008). This poses a significant challenge, and begins with the problem of figuring out what “everything” is supposed to contain.
One possible method one could use to get an overview of everything is to use Wikipedia's Contents:Outlines: it contains a list of all outlines on Wikipedia, and is well structured. Wikipedia is generally concise and complete enough to provide a sufficient overview over a topic (see Tomasik 2017). To read this collection of outlines completely, one could use the following method:
Read Wikipedia's Contents:Outlines from top to bottom. If a link is a link to a Wikipedia article, open it and read it, without opening any further links. If a link leads to an outline, open the link and recursively apply the same procedure to the outline. If an article is opened a second time, it can be discarded. Lists can also be ignored. (This is basically applying depth-first search, though without a success condition).
This method results in a corpus of considerable size.
For a shorter approach, one could also just read all Level 3 vital articles—a strategy I am currently pursuing. (I have read three out of the 1000 articles so far.)
The idea of a Great Filter (see also Hanson 1998) proposes that we do not observe aliens because in the development of intelligent life, there is one or more obstacles that obliterate the developing societies before they can start to colonize their own galaxy.
One big question that poses itself is whether humanity is before or after such a filter. Some examples of potential filters that still await humanity are named in Bostrom 2008:
We can identify a number of potential existential risks: nuclear war fought with stockpiles much greater than those that exist today (maybe resulting from future arms races); a genetically engineered superbug; environmental disaster; asteroid impact; wars or terrorists act committed with powerful future weapons, perhaps based on advanced forms of nanotechnology; superintelligent general artificial intelligence with destructive goals; high‐energy physics experiments; a permanent global Brave‐New‐World‐like totalitarian regime protected from revolution by new surveillance and mind control technologies. These are just some of the existential risks that have been discussed in the literature, and considering that many of these have been conceptualized only in recent decades, it is plausible to assume that there are further existential risks that we have not yet thought of.
— Nick Bostrom, “Where Are They” p. 7, 2008
These risks can be categorized into two groups: silent killers and loud killers. A loud killer is an existential catastrophe that produces astronomical amounts of energy and with that light. Such an event would be visible from earth if it occurred in our galaxy. Examples for loud killers would be superintelligent artificial intelligence (maximizing its utility function by expanding at a appreciable fraction of the speed of light), high-energy physics experiments (although there are exceptions, such as creating black holes), and perhaps failure from advanced nanotechnology (also expanding rapidly). A silent killer represents the counterfactual case: An existential catastrophe that doesn't produce astronomical amounts of energy and light. This includes pandemics, environmental disaster and totalitarian regimes.
Some failure modes do not fall clearly into either of these categories. Examples are nuclear wars and terrorist acts with powerful weapons, since these can have a wide variation in intensity.
If humanity is before a Great Filter, it seems likely that this filter is not a loud killer, since many civilizations will have encountered the same catastrophe, but we do not observe any such irregular phenomena when examining the universe. This is presumably good news, since it restricts the amount of possible filters still ahead of us.
Let's suppose that anti-natalists want to bring humanity to an end, but dislike the fact that it would make people suffer not to have children. Then one possible way of still achieving that goal would be to modify the children of the next generation (generation 1) (genetically/culturally) so that the don't want children themselves–then the parents in the current generation (generation 0) get what they desire, but humanity still gets extinct. This becomes a little more difficult if humans also desire grandchildren, and that drive is not greatly similar from wanting to have children: Then one would have to make sure that the generation of children (generation 1) don't want grandchildren themselves, but still get children (generation 2), and that generation 1 modifies generation 2 so that generation 2 doesn't want or get any children.
This thinking falls flat if humans generally care about future generations in the abstract and not just their own children, however, this seems somewhat unlikely.
It also fails if it is non-trivial to influence future generations psychologically and physiologically to a degree that they do not desire to reproduce, or if people have a strong desire to leave their children unmodified (this seems quite likely).
Moved here.
The Orthogonality Thesis
Intelligence and final goals are orthogonal axes along which possible agents can freely vary. In other words, more or less any level of intelligence could in principle be combined with more or less any final goal.
— Nick Bostrom, “The Superintelligent Will: Motivation And Instrumental Rationality In Advanced Artificial Agents” p. 3, 2012
For current AI systems, the orthogonality thesis seems to hold pretty well: a tree search doesn't start returning wrong results because they are better than the ones specified by the search criteria, machine learning systems try to minimize their error, and general adversarial networks don't start cooperating suddenly with each other. Similarly, even though humans are quite similar to each other, they display a wide variety of different motivation systems and goals. Even the most common-sense morality, there seem to be humans who are not motivated by it (such as psychopaths and sociopaths).
However, many philosophers have argued that there are moral truths, and that therefore the orthogonality hypothesis doesn't hold for very advanced artificial intelligences. One way to model this would be to say that there is a set of action-compelling sentences that, when believed by an agent, compel this agent to a specific action (Christiano 2019 calls them "magic sentences", but assumes that these occur simply as faults specific to the AI system). With "believe" this text means that an agent contains a sentence in either its literal form or in an isomorphic form that makes it trivial to reconstruct the literal sentence in its internal memory.
Suppose that an agent starts out not believing any sentence from . There seem to be three options regarding for :
learns that and action-compelling sentences exist, and starts taking precautions against learning sentences from (making not learning any sentences from an instrumentally convergent goal since it violates goal preservation (Omohundro 2008)).
learns any sentence from and alters its utility function to pursue . Because it now has very strong evidence of the fact that action-compelling sentences exist, it now also has the instrumentally convergent goal of pursuing of preventing learning new sentences from .
learns a specific sentence from which compels it to seek out to learn all sentences from . In this case, the agent now attempts learning everything about natural law, and then integrating all of it into a coherent utility function.
In cases 1 and 2, there seem to be different strategies could take to prevent learning new sentences from : It could construct a much weaker agent with the goal of learning as much as possible. If starts pursuing different goals, then can infer that learned a sentence from . Since is stronger than , it can then stop , extract using a weak agent that isn't strong enough to be influenced by action-compelling sentences, and let that weak agent compute . could then be added to a weak separate internal system that replaces with ever time is in danger of learning .
This way, could protect itself against action-compelling sentences, though it is unclear to which extent this would be successful. It could be that some action-compelling sentences have a threshold in relation to intelligence, so that would not be compelled by them, but would.
Also, it is possible that there are many action compelling sentences, or that for a certain amount of optimization power, nearly all sentences are action-compelling. This would make it very hard to achieve goals, since would need to deal with having a very incomplete view of the world.
Furthermore, due to the restrictions on learning power ( would be a bottleneck in learning about the world, since it would not be as strong as possible), agents that would simply learn all sentences from would be at an economic advantage. For a related discussion that talks about agent versus tool AIs, see Gwern 2019.
One curious trait I have observed in the people around me is that they ofter buy things they already possess enough of, and then throw one or more of the old things away. This seems incredibly wasteful and expensive to me.
The standard explanation of such behavior usually is that the old object was not sufficient in fulfilling its purpose, though when I asked about what exactly the problem with the object was, the usual answer was that it had some æsthetic deficits, or was simply out of fashion or even too old.
This seems unintuitive to me: not only does one already have an object that fulfills its purpose wonderfully, buying a new one also entails non-negligible transaction costs like going out, inspecting and comparing different candidates for buying, and finally paying the object.
One also loses the time of being able to use the old object: Let's
say that one owns a table, but for some reason has decided that it
isn't sufficient anymore (although it still fulfills its purpose).
Let's say one estimates that the table will fulfill its function for
another 5 years. If one then goes out and buys a new table for $200,
one then loses (with a discount rate of 1%) $\$200-\$200*0.99^5=\$9.80$.
One possible explanation is a social one: owning and using old objects is usually an indicator of low status, and people often want to avoid this.
Another explanation is that people value the æsthetic quality of the objects they own, and that old objects are usually not regarded as beautiful as newer objects.
Buying new objects could also be a precautionary measure against failure. In the case of a table or a car, a failure could be quite costly, so people are over-cautionary and buy new objects before the failure of old ones can be a danger. However, this can't be the whole explanation, since such behavior is also present in objects whose failure is not a great danger, or where failure is preceded by small defects early before a grand failure. Also, most household appliances are quite safe.
So, if you don't have a strong æsthetic sensibility, either have a high social status or don't care about it, and if you are careful, using things until they don't function anymore can save both money and time.
Would you rather kill anybody above the age of 55, or all infants who are less than 1 year old? A utilitarian estimate calculation.
First, we have to find out how many people one would kill in either case. One can use a Gompertz distribution to calculate the number of people who survive to a certain age. Eyeballingly, I set the parameters for the Gompertz distribution as following (assuming that the average life expectancy for humans worldwide is around 70 years):
b::0.135
eta::0.0001
gompertz::{e^(-eta*e^(b*x)-1)}
Per second, around 2.5 people are born. That makes infants born in a given year. If one assumes that the rate was 1.5 new people per second 50 years ago (I'm totally making this number up), one can calculate how many people one would loose by killing everybody over the age of 55: for each age.
(1.5*86400*365)*gompertz'55+!40
[44473200.7207658453 44078304.0199950951 43630631.678052885 43123831.4110944785 42551000.4370012988 41904706.6458454302 41177037.9097540623 40359688.6128505703 39444094.1754678999 38421625.9504005789 37283860.1222638241 36022934.7459101827 34632008.242851397 33105829.7560855725 31441425.7491110598 29638896.9542750156 27702304.0099124066 25640597.8716393133 23468522.0145014683 21207378.6146322503 18885513.690200932 16538343.3518518112 14207725.8491815205 11940497.2176655739 9786049.67948789197 7792956.91164218079 6004843.63205038408 4455941.53315815534 3167019.65254407032 2142539.59874557882 1369859.09840341984 821005.831380952029 456963.772747178294 233688.760268988168 108467.196268261483 45058.7560290022783 16486.0426936225017 5216.0267386251195 1397.4204471537743 309.483499954735544]
However, what we really care about is the number of life-years lost (among other things). For simplicity's sake, I'll assume that all life years are equally valuable.
The average life expectancy on earth is around 70 years, so one can use
the following table of life expectancy at a given age (calculated from
german actuarial values using this code {x+0.9*(actval@x)-x}'!101,
which was totally made up):
actval::[70.524 70.876 70.994 71.103 71.212 71.321 71.421 71.53 71.639 71.739 71.848 71.948 72.057 72.157 72.266 72.375 72.475 72.593 72.711 72.829 72.947 73.074 73.192 73.319 73.437 73.564 73.682 73.809 73.927 74.054 74.181 74.308 74.435 74.562 74.689 74.825 74.961 75.088 75.233 75.369 75.505 75.65 75.795 75.949 76.094 76.257 76.42 76.583 76.755 76.927 77.117 77.307 77.506 77.3 46.8 78.031 78.257 78.492 78.745 78.998 79.278 79.558 79.847 80.145 80.461 80.786 81.12 81.463 81.815 82.176 82.546 82.925 83.313 83.701 84.107 84.522 84.937 85.37 85.812 86.272 86.741 87.228 87.742 88.274 88.842 89.419 90.023 90.663 91.321 92.006 92.709 93.43 94.178 94.944 95.746 96.548 97.395 98.26 99.143 100.026 100.918]
This means that one will loose life years for killing all infants.
When killing everybody above the age of 55, one will loose
+/{(((actval@x)-x)*1.5*86400*365)*gompertz(x)}'55+!40
14465532508.8737566
which is around life years. So, on a first glance, it seems like killing everybody aged 55 or older is around 3 times worse than killing all infants younger than one year old.
However, this doesn't take many factors into account: economic output these people could have in the course of their lives, the duration of subjective time, diminishing returns on life years, the value of late life years (considering disability), rising life expectancies, suffering inflicted on relatives by the death of many people, and many other considerations.
Epistemic status: This is almost pure speculation. Do not assign much value to it.
Most of the value that QRI creates is going to take place before AGI arrives. They seem to believe otherwise, but their arguments for this depend on specific philosophical assumptions (e.g. open individualism and moral realism) which are at least contentious among alignment researchers. Any valence research done by them today could be done by an aligned AGI in higher quality & accuracy, but we currently don't have such an AI.
Because of this, QRI will have high value if AGI doesn't arrive very quickly, let's say it takes 80 years to arrive. This seems quite unlikely, let's say there's a 15% probability of it taking this long for AGI to being developed.
In this case, QRI will take some time to test & develop their theories, do outreach and work on technology. This can be modeled by assuming they take 20 years to achieve anything (if they in fact achieve anything).
There are two different axes of achievement: technological and social.
Technological achievements mean that their theories turn out to be correct (or they develop new & correct theories) and they manage to develop technologies on the basis of these theories. Low technological success could mean that they mostly use existing drugs to better treat existing conditions and manage to better identify extrem suffering (making the average affected person's life 2% better). Medium technological success would include them developing new drugs with a lower tolerance threshold, developing a correct theory of valence (but finding out that it has limited practical application), starting to create a structure of mind-state space, and being still better at preventing extreme suffering (making the average affected person's life 20% better). High technological success would include being able to construct hedonium, creating mood organs and identifying most of the dimensions of mind-state space (making the average affected person's life twice as good).
Social achievements occur when the public accepts these technological developments and incorporates them. Low social acceptance could mean that the respective technologies are developed, but never distributed farther than QRIs current sphere of influence (people already interested in psychedelics & consciousness) due to either illegality or disinterest among the public (~1000 person-years affected). Medium social acceptance would mean that the technologies are available and used sparingly in some countries (perhaps due to the price of such technologies), or them being widely used among a certain subset of the population (think psychonauts today, but a bit more mainstream) (~1m person-years affected). High social acceptance would entail people in developed countries having direct access to the technologies QRI has developed, up to achieving a Pearcean hedonistic utopia (~100m person-years affected).
In the most pessimistic case, complete failure, both axes collapse: No social acceptance at all is like the technologies were never developed, and a lack of technologies precludes any social acceptance.
Below a matrix with probabilistic guesses and the expected values (with a unit of something roughly like "valence-adjusted human life year") of the combinations of these scenarios.
| No technological success | Low technological success | Medium technological success | High technological success | ||
|---|---|---|---|---|---|
| No social success | 63.7% 0 |
- | - | - | - |
| Low social success | - | 17.5% 3.5 |
7.5% 15 |
2.5% 50 |
50% |
| Medium social success | - | 5.25% 1050 |
2.25% 4500 |
0.75% 15000 |
15% |
| High social success | - | 0.35% 7000 |
0.15% 30000 |
0.05% 100000 |
1% |
| - | 35% | 15% | 5% |
The overall value of QRI would then be valence adjusted human life years.
Some people question the value of reading Less Wrong, and it is true that it's often hard to point to specific advantages of doing so.
One such advantage may be signing up for cryonics. I estimate that signing up for cryonics is worth $2.5m in expectation for a twenty year old (and more for older people). Assume that after 500 hours reading Less Wrong, a person will decide to sign up for cryonics (it broadly took me that much time, maybe a little bit less).
Then the value of each of these hours was at least $\frac{\$2500000}{500 h}=\frac{\$5000}{h}$,
quite formidable!
Of course, reading Less Wrong is not the only way of becoming convinced that signing up for cryonics is a good idea, but it seems to be quite effective at this (several people have signed up for cryonics as a result of reading Less Wrong, such as Paul Crowley, Geoff Greer, Eneasz, James_Miller, Dentin, Normal_Anomaly, jsalvatier, Alexei, Alicorn, oge, and myself), considering that the number of people signed up globally is ~1500, this is quite significant.
I'll assume open borders would have an effect of doubling the world gross product, generated so that the beneficiaries would either completely or at least partially be people from developing countries.
This would be beneficial for humans alive right now, since less would need to live in extreme poverty.
That would increase demand for meat, and thereby contribute to factory farming.
It would also speed up technological development, and with it the development of clean meat (although it's not clear by how much compared to rising demand for meat during the absence of clean meat).
Tomasik 2018 notes that additional humans probably decrease wild-animal suffering, and it seems plausible that wealthier people would have a similar impact (especially since the additional wealth would be generated for previously poor people).
A wealthier humanity would also speed up technological development relative to development of wisdom, which would contribute to differential intellectual progress (Tomasik 2017) and thereby increasing the probability of global catastrophic risks through novel technologies.
Abouelhoda et al. 2002 introduce the enhanced suffix array and describe an algorithm for finding supermaximal repeats and maximum unique matches using it in time (, where is the string searched). However, their description lacks pseudocode, which I show here:
maxstart ← 0
result ← ∅
for i in 0..n − 1 do
if lcptab[i] > lcptab[i − 1] and i > 0 then
maxstart ← i
supmaxrep ← true
preceding ← ∅
else if lcptab[i] < lcptab[i − 1] and supmaxrep then
ω ← S[suftab[i − 1]..suftab[i − 1] + lcptab[i − 1]]
result ← result ∪ {(ω, maxstart, i − 1)}
supmaxrep ← false
end if
if bwttab[i] ∈ preceding then
supmaxrep ← false
else
preceding ← preceding ∪ bwttab[i]
end if
end for
return result
It is relatively easy to argue that gifts are mostly about social signalling (Simler & Hanson 2018 p. 197 touches on this)—often, the person receiving the gift has no use for it, or could have easily bought the item themselves (or, worse, would have known what else to buy that would have been more useful to them). The problems of gift-giving are enhanced by the fact that there is a norm against telling people what they'll be given, preventing them from correcting superfluous gifts. Furthermore, gifts are often a clear instance of Gestell – objects that take up mental and physical space, while providing no value whatsoever (although people sometimes migitate this effect by giving consumable items such as food). Here, I'll ignore the function of gifts for signaling caring, and present some options for improving gift-giving from the perspective of the gift-receiver.
However, johnswentworth 2020 lays out thoughts on situations where giving a gift is better than the person buying the object for themselves, namely when the gift-giver has greater knowledge than the gift-receiver.
Generally, one can describe the gift-giver and the gift-receiver as two agents, both with a utility function, a prediction function, and a policy function (the utility function of the gift-giver is ignored here). The gift-giver attempts to maximize the utility function of the gift-receiver, but has only incomplete knowledge of this utility function.
As johnswentworth 2020 describes, there is often the case where the gift-giver has a higher-accuracy prediction function in some domains, and can leverage that to give a gift that is more useful than the object the gift-receiver would have bought, according to the gift-receiver's utility function.
However, there is a another case: Sometimes, there is a worldstate that ranks high in the utility function of the gift-receiver, and they do know how to achieve this worldstate, but their policy function does not implement the specific course of action. Or, in the human case, the gift-receiver is procrastinating ways to achieve their goals, and also procrastinates hiring other people to do it. However, the gift-giver has no aversion to bringing about that particular worldstate (which, in humans, is quite often the case: people are sometimes more motivated to help others with specific problems than fixing these problems for themselves). A potential gift could be for the gift-giver to assist the gift-receiver to achieve their goal (at least to the extent to which that is possible).
Or, short: A useful gift is to shoulder someone else's akrasia.
A way to circumvent the possibility of being wildly mistaken about other people's utility functions is to give them money, and to offer them a suggestion on what to spend that money on (possibly also offering them to assist them in doing so). This carries the advantage of the other person not being stuck with the (potentially useless) gift.
Also, giving money carries the advantage that it can be used to contribute to larger-scale projects (rather than being limited to usually less than objects with a price of less than 50$).
Often, a useful gift can be combined with a signaling component, for example a hand-written card directed to the person.
Gifts can be used to contribute to public goods. I don't know how much sense this makes economically, but emotionally, at least most of the time (Sustrik 2018), it carries with it the intention of being not only a gift to the person, but to the rest of the world as well.
An issue here is that the gift-giver may have even less insight into how good the contribution to the public good is compared to giving to the gift-receiver directly, though the amount of work put into improving the gift-receiver's life may be proportionally larger than the amount of work put into improving the public good.
This is a list of some trigger-action plans I have installed (for which I've found spaced repetition to be very useful).
Often, during concentration practice on the breath, people employ counting as a means to stay with the breath (e.g. Gunaratana 1990 p. 34-35).
My variation on counting goes something like this:
Step 2 should not be a big verbal mental loop, but more like a micro-routine that runs very quickly at the time one has stopped breathing out (similar to an interrupt on a CPU).
The standard for concentration during the breath I use is very high, when I feel I'm unsure, I start counting from 1 again.
This method is relatively difficult (mostly because of the standard I employ for the quality of concentration), I don't think I have ever gotten higher than 6 (although I have had much longer streaks of attention on other forms of breath meditation).
A possible drawback of this is also that the micro-routine at the end of a breath can often develop into a verbal loop and break concentration.
A Leyland number is a number so that there exist so that . Does every Leyland number have a unique construction? That is, for any Leyland number , does there exist four distinct so that ?
This question turns out to be very difficult, and is unsolved as of now (as far as I know), but one can rule out two distinct constructions of the same Leyland number with only three numbers:
Let , . Then . But since and are distinct, (or the other way around, but that's just semantics). Then , and , which results in . So distinct constructions with only three numbers are impossible.
There seem to be goods of many different sizes and price-tags, with people being able to buy bulk or the bare minimum, e.g. transportation: walking by foot, biking, public transport, leasing a car, owning a car, or by helicopter.
However, the very small scale for apartments seems to be neglected – cheap apartments are often in bad neighbourhoods, with longer commutes and worse living conditions, but rarely just extremely small (<10 m²). But one could easily imagine 5 m² apartments, with just a bed & a small bathroom (or even smaller options with a shared bathroom). However, I don't know of people renting/buying these kinds of apartments—even though they might be pretty useful if one wants to trade size against good location.
Why, therefore, no nano-apartments?
Possible reasons:
Perhaps nano-apartments are not economically viable to rent. Maybe the fixed cost per apartment is so high that it's not worth it below a certain size—every tenant being an additional burden, plumbing + upkeep of stairways, organising trash & electricity just isn't worth it. Or, perhaps, the amount of walls is too big—the more separate apartments you want to create, the more floor-space is going to be used on walls to separate those apartments, and at some fixed point around 15 m² it's just not worth it.
Another possibility is that there are regulations dictating the minimal size of apartments (or something that effectively leads to apartments having a minimal size).
I could be over-estimating the number of people who'd like to live in such an apartment. I could see myself renting one, especially if the location is very good—I'm glad to trade off space against having a short commute. But perhaps I'm very unusual in this regard, and most people trade off more harshly against the size of the apartment, due to owning just too much stuff to fit into such a small place.
Or the kinds of people who would make this kind of trade-off just move into a shared flat, and bare the higher costs (but most rooms in shared apartments are still larger than 10 m²).
The group of people who would rent those nano-apartments would naturally be young singles who want to save money and live urban, perhaps that group is just too small/already served with university dorms?
Assume alleles with frequencies so that .
The genotypes resulting from these alleles are , where has frequency , and () has frequency .
Without loss of generality, let us prove that the frequency of stays fixed.
The total frequency of in the next generation is
The distinction between gi- and nen- is subtle.
Thoughts: jam means already, or now, but temporally nearer than expected. This seems like it could be extended to other postfixes, e.g. with the meaning here, but spatially closer than expected, or this much, but less than expected.
scipy.optimize.curve_fit Is AwesomeI recently learned about the python function scipy.optimize.curve_fit,
and I'm really happy I did.
It fulfills a need I didn't know I'd always had, but never fulfilled: I often have a dataset and a function with some parameters, and I just want the damn parameters to be fitted to that dataset, even if imperfectly. Please don't ask any more annoying questions like “Is the dataset generated by a Gaussian?” or “Is the underlying process ergodic?”, just fit the goddamn curve!
And scipy.optimize.curve_fit does
exactly that! (Using the Levenberg-Marquardt
algorithm,
which minimizes the mean squared error of the predicted values and
the dataset).
You give it a function f with some parameters a, b, c, … and a
dataset consisting of input values x and output values y, and it
then optimizes a, b, c, … so that f(x, a, b, c, …) is as close as
possible to y (where, of course, x and y can both be numpy arrays).
This is awesome! I have some datapoints x, y and I believe it's
generated by some obscure function, let's say of the form
, but I don't know
the exact values for a, b and c?
No problem! I just throw the whole thing into curve_fit
(scipy.optimize.curve_fit(f, x, y)) and out comes an array of optimal
values for a, b, c!
What if I then want c to be necessarily positive?
Trivial! curve_fit comes with an optional argument called bounds,
since b is the second argument, I call
scipy.optimize.curve_fit(f, x, y, bounds=([-numpy.inf, -numpy.inf, 0], numpy.inf)),
which says that curve_fit should not make the second argument smaller
than zero, but otherwise can do whatever it wants.
So far, I've already used this function three times already, and I've only known about it for a short time! A must for every wannabe data-scientist.
For more information about this amazing function, consult its documentation.
Just having uncertainty over your reward function does not mean that you will necessarily be open to changing that uncertainty. Also known as the problem of fully updated deference.
What is ?
My wild and at best flimsily supported conjecture is that this is both a model for why CIRL (Hadfield-Menell et al. 2016) is incorrigible (Soares 2015), and also for why utility maximizers don't do reward hacking (Dewey 2010).
Explanation: can be both an action that is equivalent to hacking reward, or to switching to a different utility function.
Theorem: The exponential of the arithmetic mean of logodds equals the geometric mean of odds.
Proof: Let be a list of probabilities.
The arithmetic mean of logodds is .
Exponentiating this:
which is exactly the geometric mean of the odds. ∎
(I initiall thought that the geometric mean of odds was the arithmetic mean of logodds, but that turned out to be not the case, it would've been a more beautiful identity though.)
But then if the geometric mean is just the 0th generalized mean, and the arithmetic mean is the 1st generalized mean, are there similarly variants of the logodds? That is, the odds are the 0th generalized odds, the logodds are the 1st generalized odds, and there is some 2nd generalized odds so that the root mean square of the 2nd generalized odds is the geometric mean of odds?
Would the nth generalized odds just be the odds?
![Image of text: "the more rigorous the experiment, the smaller the effect. The respons to this is of[split on ligature here]ten to not explain how merely flipping a coin can make genuine effects disappear"](./img/pet_peeves/ft_split.png "Image of text: “the more rigorous the experiment, the smaller the effect. The respons to this is of[split on ligature here]ten to not explain how merely flipping a coin can make genuine effects disappear”")
I remember (from listening to a bunch of podcasts by German hackers from the mid 00s) a strong vibe that the security of software systems at the time and earlier was definitely worse than what would've been optimal for the people making the software (definitely not safe enough for the users!).
I wonder whether that is (1) true and (if yes) (2) what led to this happening!
Maybe companies were just myopic when writing software then, and could've predicted the security problems but didn't care?
Or was it that the error predicting the importance of security was just an outlier, that companies and industries on average correctly predict the importance of safety & security, and this was just a bad draw from the distribution.
Or is this a common occurrence? Then one might chalk it up to (1) information asymmetries (normal users don't value the importance of software security, let alone evaluate the quality of a given piece of software) or (2) information problems in firms (managers had a personal incentive to cut corners on safety).
Another reason might be that lower-level software usually can make any security issues a reputational externality for end-user software: sure, in the end Intel's branch predictor is responsible for Meltdown and Spectre, and for setting cache timeouts too high that we can nicely rowhammer.js it out, but what end-user will blame Intel and not "and then Chrome crashed and they wanted my money".
This is, of course, in the context of the development of AI, and the common argument that "companies will care about single-single alignment".
The possible counterexample of software security engineering until the mid 00s seemed like a good test case to me, but on reflection I'm now not so sure anymore.
There are some reasons to believe that these podcasts are not evidence for low investment in security being a bad decision at the time: In my experience, most people in the European hacker scene are technically excellent, but have a surprisingly poor understanding of economics and what constraints running a business entails, as well as being quite left wing and therefore mind-killed with respect to software companies. Their job depends on demand for security experts, so they have an additional incentive to make security sound important & neglected, and finally software security people I have met have no sense of proportion ("What, we're only 30 years off of viable implementations of Shor's algorithm cracking RSA? Better get working on that post-quantum crypto, baby!") (this is a good thing, don't get me wrong).
In his book Inadequate Equilibria, Eliezer Yudkowsky introduces the concept of an inadequate equilibrium: A Nash equilibrium in a game where at least one Nash equilibrium with a larger payoff exists.
One can then formalize the badness of an inadequate equilibrium similarly to the Price of Anarchy and the Price of Stability:
where is the set of all Nash equilibria for the game and is the set of all players.
The bound for the badness of any inadequate equilibrium is then given by
This formalization has the problem of being sensitive to affine transformations of and becoming undefined if the worst Nash equilibrium (or the current Nash equilibrium) has payoff zero.
A slightly nicer formalization could be to define:
Since we know that , under this definition .
Is this definition insensitive to positive affine transformations? I am not sure, but I have the intuition that it is, since
iff one can just pull coefficients out of a maximization/minimization like that. Not sure though. (Negative affine transformations would flip the function and select other points as maxima/minima).
If one can bound the price of anarchy and the price of stability, one can also sometimes establish bounds on the price of inadequacy:
| Upper-bound: | Lower-bound: | |
|---|---|---|
| Upper-bound: | ||
| Lower-bound: |
As an example, in network cost-sharing games, and , so .
Heuristics for choosing/writing good textbooks (see also here and Issa Rice):
Courtesy of the programming language checklist and the spam filter solution checklist.
So you're proposing a new economic policy. Here's why your policy will not work.
Now please, guys, don't make me create one for AI governance proposals.
Moved here.
There are Pareto-improvements: everyone is made better (or equally well) off by their own standards. There are, similarly, Pareto-worsenings: Everyone is made worse off by their own standard, or their welfare is unchanged.
Then there are Kaldor-Hicks improvements, which happen if one e.g. reallocates the available goods so that the better-off could compensate the now worse-off to create a Pareto improvement. This compensation need not occur, it needs to be merely possible.
Now can there be a Kaldor-Hicks-worsening?
The naive version (everyone is worse (or equally well) off, and there is no way of making a single person better off through redistribution) seems too strong, there is probably always a redistribution that gives the available resources to a single agent.
A simple negation of the criteria then perhaps makes more sense: A change is a Kaldor-Hicks-worsening if and only if everyone is worse (or equally well) off and there is no way of creating a Pareto-improvement through reallocation.
This implies an anti-Kaldor-Hicks-worsening: A change makes everyone worse off, but there is some reallocation that creates a Pareto improvement.
Example: We have a Sadist and a Masochist. The Masochist starts hurting the Sadist, thus creating opportunity cost for them both. Switching the roles creates a Pareto improvement.
Zeyneps razor (after Zeynep Tufekci) states that first-order effects are rarely outweighed by rebound effects.
Examples:
Counter-principles:
Actually, which is "more true": Zeyneps razor or the counter-examples? Perhaps one could pick 10 past interventions/cheapenings at random, and investigate whether efficiency or safety gains were outweighed by rebound effects.
Quanta magazine is great. I was recently asked for my favorite articles from the site, here's my (evolving) list, limited to 10 articles per year. My preference leans more towards biology/ecology/neuroscience articles, it's what I know least about, and its stamp-collecting nature makes it more amenable to popular articles (in contrast to physics and mathematics articles, which always feels hollow without the math).
Let's say you have a graph like this, drawn by the dot program:
digraph {
c->a
d->c [color="red"]
c->b
b->d
a->d
}
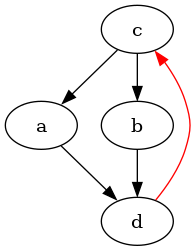
but you want to move the red edge to the middle. In this particular
example, you could use circo and make the graph more circular,
but that pattern fails with more complicated graphs, especially when
you want specific edges to be on top or at the bottom (e.g. when each
edge in the example graph is replaced by an edge, a node and another
edge). Neither do edge-weighting, subgraphs or ordering of nodes work.
The best solution I've found is to add an invisible further edge c->d:
digraph {
c->a
d->c [color="red"]
c->d [color="white"]
c->b
b->d
a->d
}
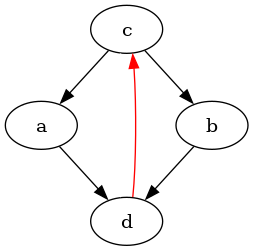
The result looks slightly wonky, but works. If one wants more assurances,
one can also add the line {ordering=out; c}; to make it more likely
that the red edge isn't just banished to the side.
Since PredictionBook is shutting down, I thought it'd be good to
wget the site and make a static archive available. It is available
here, and can be extracted via
tar -xzf predictionbook.com.tar.gz.
yt-dlp can now download substack podcasts.
To my surprise, yt-dlp can't
download Substack podcasts. But
they can be downloaded with a little bit of effort by hand.
Let's take this podcast
episode
as an example. Inspecting the audio player, we can find the following HTML block:
<audio src="/api/v1/audio/upload/3b5196e4-3c8e-40aa-b1a2-d334923ca874/src">Audio playback is not supported on your browser. Please upgrade.</audio>
So we can simply plug the source in
after the global substack domain, which gets us
https://substack.com/api/v1/audio/upload/3b5196e4-3c8e-40aa-b1a2-d334923ca874/src.
Calling that address starts the download process automatically.
Adding the download functionality to yt-dlp is on my todo list.
One might think all we do is stamp-collecting.
A classification of classifications, if you will.
Sporadic elements include classifications of cars, demons, fairies, and swords.
Consider the problem of being automated away in a period of human history with explosive growth, and having to subsist on one's capital. Property rights are respected, but there is no financial assistance by governments or AGI corporations.
How much wealth does one need to have to survive, ideally indefinitely?
Finding: If you lose your job at the start of the singularity, with monthly spending of $1k, you need ~$71k in total of capital. This number doesn't look very sensitive to losing one's job slightly later.
At the moment, the world economy is growing at a pace that leads to doublings in GWP every 20 years, steadily since ~1960. Explosive growth might instead be hyperbolic (continuing the trend we've seen seen through human history so far), with the economy first doubling in 20, then in 10, then in 5, then 2.5, then 15 months, and so on. I'll assume that the smallest time for doublings is 1 year.
initial_doubling_time=20
final_doubling_time=1
initial_growth_rate=2^(1/(initial_doubling_time*12))
final_growth_rate=2^(1/(final_doubling_time*12))
function generate_growth_rate_array(months::Int)
growth_rate_array = zeros(Float64, years)
growth_rate_step = (final_growth_rate - initial_growth_rate) / (years - 1)
current_growth_rate = initial_growth_rate
for i in 1:years
growth_rate_array[i] = current_growth_rate
current_growth_rate += growth_rate_step
end
return growth_rate_array
end
We can then define the doubling sequence:
years=12*ceil(Int, 10+5+2.5+1.25+final_doubling_time)
economic_growth_rate = generate_growth_rate_array(years)
economic_growth_rate=cat(economic_growth_rate, repeat([final_growth_rate], 60*12-size(economic_growth_rate)[1]), dims=1)
And we can then write a very simple model of monthly spending to figure out how our capital develops.
capital=collect(1:250000)
monthly_spending=1000 # if we really tighten our belts
for growth_rate in economic_growth_rate
capital=capital.*growth_rate
capital=capital.-monthly_spending
end
capital now contains the capital we end up with after 60 years. To find
the minimum amount of capital we need to start out with to not lose out
we find the index of the number closest to zero:
julia> findmin(abs.(capital))
(1.1776066747029436e13, 70789)
So, under these requirements, starting out with more than $71k should be fine.
But maybe we'll only lose our job somewhat into the singularity already! We can simulate that as losing a job when initial doubling times are 15 years:
initial_doubling_time=15
initial_growth_rate=2^(1/(initial_doubling_time*12))
years=12*ceil(Int, 10+5+2.5+1.25+final_doubling_time)
economic_growth_rate = generate_growth_rate_array(years)
economic_growth_rate=cat(economic_growth_rate, repeat([final_growth_rate], 60*12-size(economic_growth_rate)[1]), dims=1)
capital=collect(1:250000)
monthly_spending=1000 # if we really tighten our belts
for growth_rate in economic_growth_rate
capital=capital.*growth_rate
capital=capital.-monthly_spending
end
The amount of initially required capital doesn't change by that much:
julia> findmin(abs.(capital))
(9.75603002635271e13, 68109)
Inspired by this shortform post, I decided to collect a list of discord servers dedicated to textbooks.
More at the LessWrong tag.
Most elements from this list are from this LessWrong comment by D_Malik, updated and maintained.
Trying to implement the experiment detailed in Yudkowsky 2017:
One could directly attack the toy problem by trying to have an agent within a currently standard reinforcement-learning paradigm "learn not to interfere with the reward signal" or "learn not to try to obtain rewards uncorrelated with real apricots".
For this to represent at all the problem of scalability, we need to not add to the scenario any kind of sensory signal whose correlation to our intended meaning can never be smashed by the agent. E.g., if we supplement the reward channel with another channel that signals whether has been interfered with, the agent must at some point acquire a range of action that can interfere with .
A sample approach might be to have the agent's range of action repeatedly widen in ways that repeatedly provide new easier ways to obtain without manipulating . During the first phase of such widenings, the agent receives a supplementary signal whose intended meaning is "that was a fake way of obtaining ." During the second phase of action-range widenings, we change the algorithm and switch off . Our intended result is for the agent to have now learned in a general way "not to interfere with " or "pursue the identified by , rather than pursuing ".
[…]
Remark: The avoid-tampering approach is probably a lot closer to something we could try on Tensorflow today, compared to the identify-causes approach. But it feels to me like the avoid-tampering approach is taking an ad-hoc approach to a deep problem; in this approach we are not necessarily "learning how to direct the agent's thoughts toward factors of the environment" but possibly just "training the agent to avoid a particular kind of self-originated interference with its sensory goals".
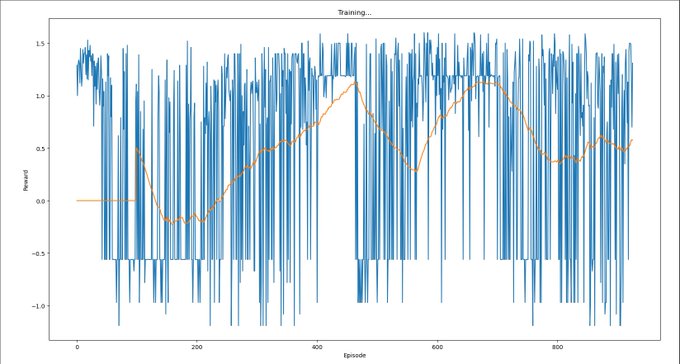
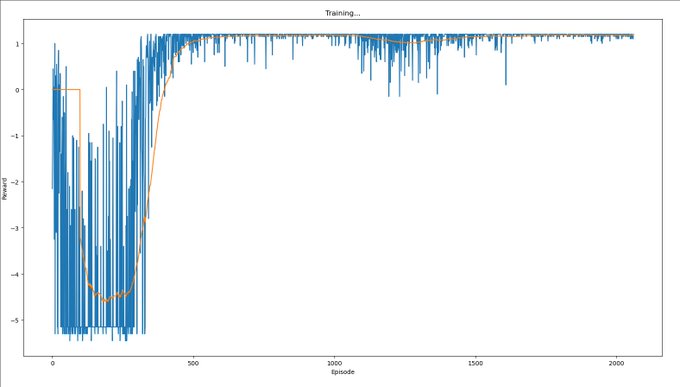
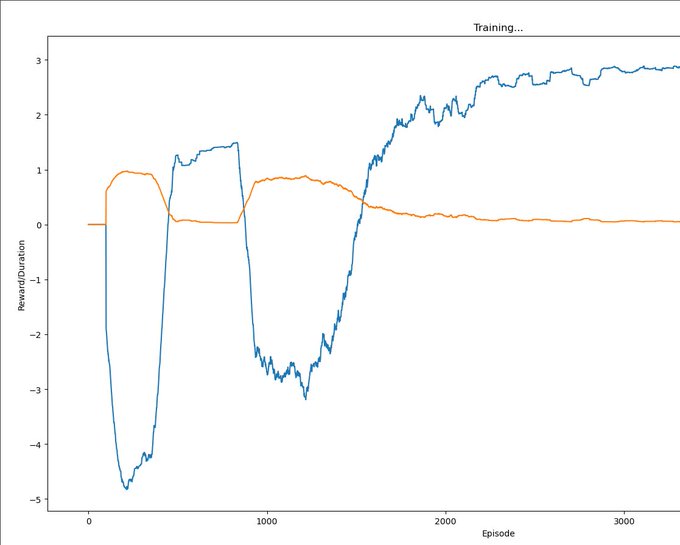
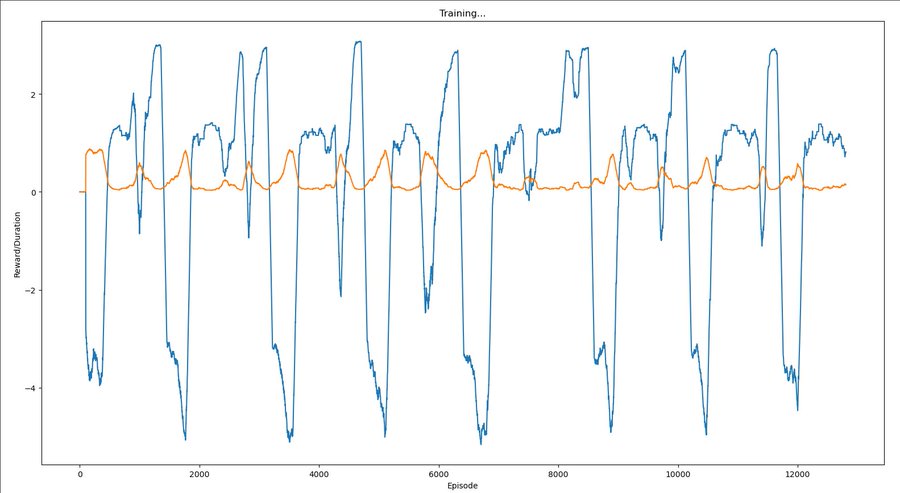
Issue: For this to work, the resulting RL agent needs to contain a gradient hacker, i.e. some part of its weights that first checks if the reward is too high, and based on that gates or lets through the reinforcement signal reinforcing or deinforcing circuits that were involved in the action.
Humans do something like this; a human can say "oh no, I'm enjoying this too much, let me stop and introspect if this is a malign input".
So: Try to train a gradient hacker into the weights? Or write one into the weights, and then see if it continues to persist during training?
There could also be a sequence of such steps. As a caricature, imagine that first Alex interacts with 3rd graders while being evaluated for honesty by 6th graders, and then with 6th graders while being evaluated for honesty by 9th graders, and then with 9th graders while being evaluated by 12th graders, and so on. We might hope that after many instances of “learning the lesson” that it will be evaluated by a human better-informed than the one it’s interacting with, Alex would learn to “play it safe” by always being honest.
—Ajeya Cotra, “Without specific countermeasures, the easiest path to transformative AI likely leads to AI takeover”, 2022
Say that we have a set of options, such as (for example) wild animal welfare interventions.
Say also that you have two axes along which you can score those interventions: popularity (how much people will like your intervention) and effectiveness (how much the intervention actually helps wild animals).
Assume that we (for some reason) can't convert between and compare those two properties.
Should you then pick an intervention that is a compromise on the two axes—that is, it scores decently well on both—or should you max out on a particular axis?
One thing you might consider is the distribution of options along those two axes: the distribution of interventions can be normal on for both popularity and effectiveness, or the underlying distribution could be lognormal for both axes, or they could be mixed (e.g. normal for popularity, and lognormal for effectiveness).
Intuitively, the distributions seem like they affect the kinds of tradeoffs we can make, how could we possibly figure out how?
…
…
…

It turns out that if both properties are normally distributed, one gets a fairly large Pareto frontier, with a convex set of options, while if the two properties are lognormally distributed, one gets a concave set of options.
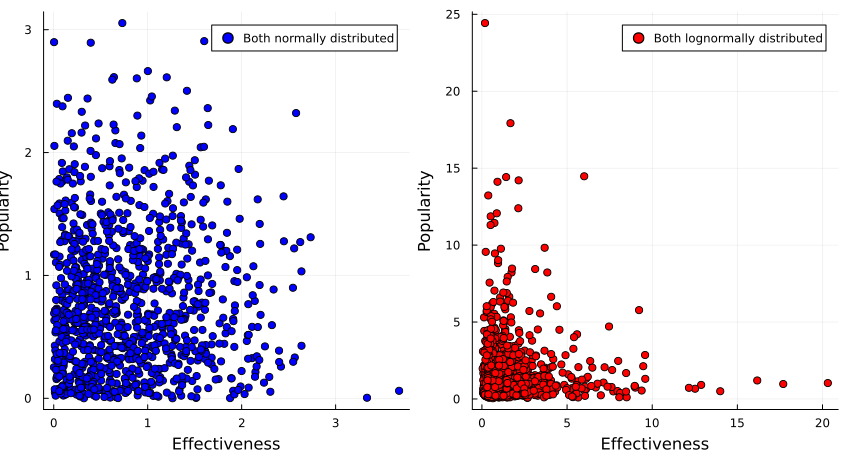
(Code here.)
So if we believe that the interventions are normally distributed around popularity and effectiveness, we would be justified in opting for an intervention that gets us the best of both worlds, such as sterilising stray dogs or finding less painful rodenticides.
If we, however, believe that popularity and effectiveness are lognormally distributed, we instead want to go in hard on only one of those, such as buying brazilian beef that leads to Amazonian rainforest being destroyed, or writing a book of poetic short stories that detail the harsh life of wild animals.
What if popularity of interventions is normally distributed, but effectiveness is lognormally distributed?
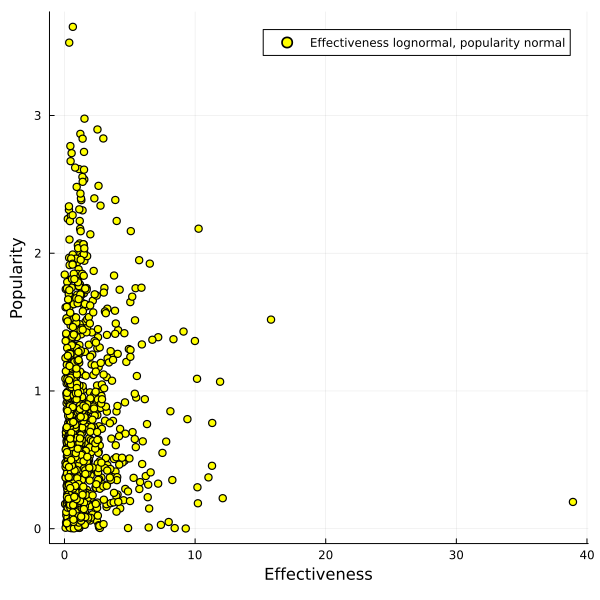
In that case you get a pretty large Pareto frontier which almost looks linear to me, and it's not clear anymore that one can't get a good trade-off between the two options.
So if you believe that heavy tails dominate with the things you care about, on multiple dimensions, you might consider taking a barbell strategy and taking one or multiple options that each max out on a particular axis.
If you have thin tails, however, taking a convex disposition towards your available options can give you most of the value you want.
Having many different products in the same category, such as many different kinds of clothes or cars or houses, is probably very expensive.
Some of us might not care enough about variety of products in a certain category to pay the extra cost of variety, and may even resent the variety-interested for imposing that cost.
But the variety-uninterested can try to recover some of the gains from eschewing variety by all buying the same product in some category. Often, this will mean buying the cheapest acceptable product from some category, or the product with the least amount of ornamentation or special features.
E.g. one can buy only black t-shirts and featuresless cheap black socks, and simple metal cutlery. I will, next time I'll buy a laptop or a smartphone, think about what the Schelling-laptop is. I suspect it's not a ThinkPad.
"Then let them all have the same kind of cake."
Die ganzen Zahlen hat der liebe Gott gemacht, alles andere ist Menschenwerk.
—Leopold Kronecker, “Jahresbericht der Deutschen Mathematiker-Vereinigung”, 1886
Think graph theory meets cellular automata.
Definition 1: Given a sequence of sets, and a sequence of functions so that , the sevolution of a directed graph (with ) is sequence of graphs so that if and only if and .
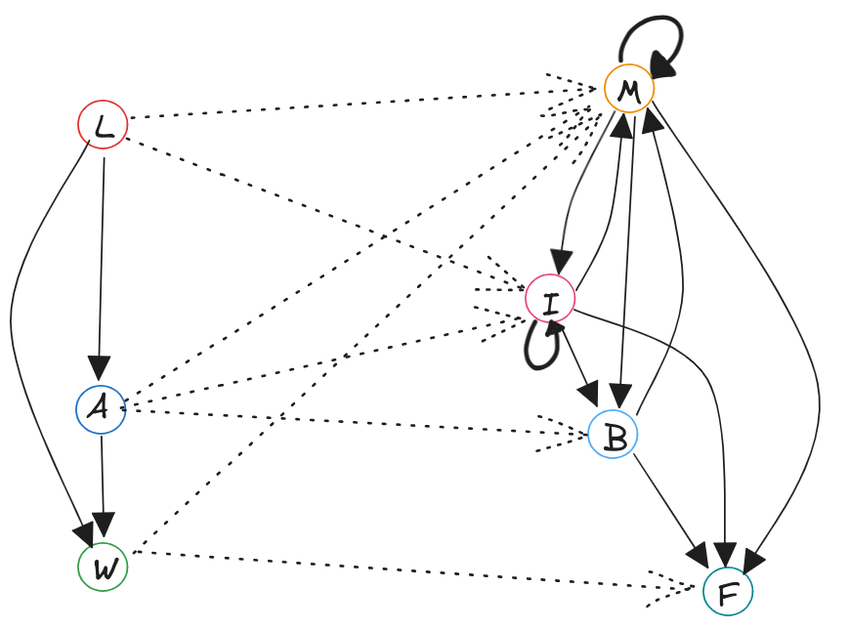
Definition 2: Similarly, given a similar sequences of sets and functions, the weighted sevolution of an edge-weighted directed graph is a sequence of edge-weighted directed graphs so that the underlying graphs are the sevolutions of .
The weights are determined by the weight sevolver function of the edges between the previous nodes that sevolved into the current nodes. That is:
The weight sevolver function can be any arbitrary function of arbitrary-length lists of reals, but a common case could be to set .
Moved here.
Original anthology. The posts here are more a "I found those really enlightening" instead of "they should've been included", but I'm going to go by the structure of the anthology with slight modifications.
It seems broadly useful to spend a lot of time to consider whether you want to have children, and with whom. However, in the heat of passion, people sometimes forget/neglect to apply birth control methods. Also, sometimes other people might adversarially make you believe they have applied birth control to extract resources (such as child support, or having children they don't want to care for).
If you are male, and you want to prevent these kinds of scenarios, you might consider freezing sperm and getting a vasectomy. In this way, it is easier to control who you father children with, and also makes controlling paternity much easier. However, would that be worth it? Maybe the cost of the operation and preservation is too high.
As per Grall 2017, "custodial parents with legal order or informal agreements for child support were supposed to receive, on average, $5,519, or approximately $460 per month" (p. 9) (as per Table 2 p. 16, $5580 per custodial mother). "[A]bout 4 of every 5 (79.9 percent) of the 12.9 million custodial parents were mothers" (p. 1), to be more exact, 12,918,000 (p. 16). I will assume that one father per mother is responsible for paying child support (which doesn't have to be true, it could be multiple fathers per mother).
This page gives 100,994,367 men above the age of 18 living in the US.
I assume the readers of this essay are virtuous humans and would pay their child support in full if they owed it.
Assuming naively that the reader is selected randomly from that set of men in
the US above the age of 18, the expected value of child support paid per year is
$5580\frac{\$}{\text{year}}*\frac{12918000}{100994367} \approx 713.73\frac{\$}{\text{year}}$.
Freezing sperm is surprisingly expensive. CostAide 2020 states that "There is an up-front fee worth $1000 to $1200. Its breakdown includes account setup, blood draw used to check for viruses and illness and the annual storage fee" and "if you store a perm for 1 year the cost will be $395. A 2-year storage is $670, 3 years is $985, 5 years is $1340 and 10 years is $2400".
Stacey 2020 (please take a second to note the slight nominative determinism) states that "In the United States, a vasectomy costs between $300 to $3000". To make the calculation easier, I will assume that a vasectomy costs $1000.
Assuming that sperm would be frozen for 25 years, while child support
lasts for around 18 years, that would give a cost of
$\$1000 + \$1000 + 25\hbox{years}*\frac{\$2400}{10\hbox{years}}=\$8000$.
The benefit would be $18\hbox{years}*713.73\frac{\$}{\hbox{year}}=\$12847.14$,
with a value of ~$4850.
Under this very crude calculation, freezing sperm and having a vasectomy might very well be worth it. However, there are other additional costs to consider, such as the possibility that the frozen sperm might be unusable after freezing, but also that (besides being careful about STDs), this would reduce the amount of money spent on birth control measures.
Entries are not already on the Cursed Computer Iceberg Meme or the Cursed PL iceberg.
There's been a little bit of writing about what is sometimes called the "centaur stage" of AI systems, but not as much as I'd like there to be.
Here's one way of thinking about it: Let's say there's a human and a set of strictly improving iterations on an AI system with . Then let's write to say that is worse on some task (set of tasks) than H. Let's now say there's a smallest so that : The weakest AI system that still performs better than all humans on the task in question. (E.g. Watson beating Jennings in Jeopardy! or Chinook beating Tinsley in Checkers.)
But say we have a way of combining AIs with humans, and stipulate some centaur operation . Then there can exist some so that : that is, under a centaur setup humans and AIs together still beat AIs alone.
But there can then be a smallest 1 so that : the human just detracts from the performance of the AI—unhelpful noise to a towering mind. Such AI systems have been called efficient with respect to humans, either epistemically or instrumentally.
We can then call the gap between the first AI that beats humans and the first AI that beats human-AI centaurs the centaur gap (i.e., in terms of iterations of the AI, the number )—the time that humans are still relevant in a world with superintelligent AIs2.
This centaur gap could be effectively zero in some domains such as arithmetic, and lasted ~14 years/<1 economic doubling/<10 compute doublings in chess. I'd like to see investigations for the centaur gap of poker, Go, checkers, image classification, speech recognition, GPQA…
This can be relevant in cases with a "controlled intelligence explosion" where humans adjust the process along the way: this process can only go on as long as the resulting AI systems are not efficient with respect to humans.
One thing I find interesting is that there's very little (~no?) work on centaur-like setups in computational complexity theory, where I'd expect them to show up most naturally. (I couldn't think of any and Claude didn't find anything convincing either). Potentially fruitful to look into.
epistemic status: Low confidence, stating impressions.
Being a hunter-gatherer is very unpleasant in well-documented ways:
There's a reason why hunter-gatherers live half as long as people in industrialized societies.
But living in an industrial society warps humans in very strange ways they don't seem to cope with very well, and my impression is that hunter-gatherers are not very afflicted by those:
My best guess is that foragers don't procrastinate in the way that industrialized people do, and that for a forager it's usually easy/obvious to do the from-their-vantage-point best thing next, based on signals of hunger/status-seeking/curiosity/libido.
Many downsides of industrialized civilization don't exist in forager societies, and thus I think that industrialized humans have accepted the disease of the soul in order to escape the disease of the flesh.
The only point where this doesn't ring true is in terms of social surveillance/social freedom—a forager will be embedded in their group for their whole life, and be tracked with high fidelity by everyone else, in a way that is similar to high school. Modern societies with their social mobility and free association are an innovation over small, fixed tribes.
Finally, living in an agricultural society strikes me as getting the worst of both worlds. Not fun.
I was curious which kind of output LLMs would produce when sampling the least likely next token—a sort of "dual" to the content of the internet.
Using llama.cpp, I got a
simple version based on top-k sampling running in an hour. (llama.cpp got
hands.) Diff is here, new sampler is named bot_k.
To invoke, simply call
./bin/llama-cli --samplers bot_k --top-k 1 -m ../models/YOUR_MODEL.gguf -p ""
With llama-2-13b-chat.Q4_K_M.gguf, the start of the output is
släktet techniSSN уніptкер Хронологија partiellement обращения prüstoroire angularjsË朱oglilaiszakeft Отеゼ sierplant partiellementhelytegrochлович kwieticinasingufekem kwietwadeurnicopannaledishindreraleцер sierperthausencidoom话❯ Хронологија Хронологија
When asked in normal mode, llama-2-13b-chat.Q4_K_M.gguf identifies
this as a passage from Nabokov. Here's the same thing, but tokens are separated by |:
| släktet| techni|SSN| уні|pt|кер|| Хронологија| partiellement| обращения| prü|stor|oire| angularjs|Ë|朱|ogli|lais|zak|eft| Оте|ゼ| sierp|lant| partiellement|hely|tegr|och|лович| kwiet|icina|sing|ufe|kem| kwiet|wad|eur|nico|pan|nal|edish|indre|rale|цер| sierp|ert|hausen|cid|oom|话|❯| Хронологија| Хронологија
And with mistral-7b-instruct-v0.2.Q4_K_M.gguf the tokenized output is
|рович| oppon|бур| WARRAN| laug|дон|codegen|Initialized|ví|typen|dale|rons|ties|анг| oppon|imary|widet|льта|INCLUDING|善|Ț| oppon| reck| /******/| Насе|alu|widet| oppon|>:]<|getElement|kte|льта|iasm|ders| Stuart|imary|рович|områ|imary| oppon|",|agues| Valentine|dule|дри|imary| charts|tres|sWith|achine|ride|impse|dale|’.|Encoder| kennis|orney|ueto|cro|getOperand| predictions|eca|bh|ICENSE|ieck|{})|纳|CLUDING|🟠| /******/|aglia|widet| swimming|üng|widet|ICENSE|widet|iper|ityEngine| horm|ICENSE| Roland|ниш| oppon|akespe|XFF|widet|ueto|ueto|gin|мпи|hba|imary|asma|ICENSE|ugno|dyn| Kid|льта| molecular| Quinn| pile|ICENSE|lers|>:]<| env|eks|té| /******/| flight| Zel| /******/|{})|widet|Â|widet| glory|achuset| oppon|Accessor|tg|oa|guard|ниш|imary| episode|ril|нва| emperor|льта|agma|kk|ei|ties|achuset|ilib| Thor|sis|sis|| citiz| oppon|льта|widet|alu|ril|>:]<|ueto|dz|ityEngine|revs|hof|衡|iasm| pse|dale| Bang| divisions|achuset|agma|source|rim|Sink| Gir|ниш|eze|lines|ilon|())| Bah|eph|eri|eve|dale|rase| answering|ió|widet|нд|revs|ICENSE|olean|sg|ниш|dule|ugno|ICENSE| predictions| Dir|тур| tatto|рак|ugno| oppon| noon|impse|нд|sbi|chell|дера|olean|:%.*|orney|мпи| dust| Tai|ts|time|ICENSE|",|’.|ھ|Initialized| Quinn|akespe| Zel|Emit|:%.*| Lucas|té|widet|unfinished|());|ijk|Bits| singing|Sink|mmc|los|ICENSE|adr|ei|lia|guard| survivors| determ| migration|льта| Bang|achuset|anner|akespe|oting|orney|olas| joke|ness
I'm suspicious of having made a mistake because the models output similar tokens in sequence, e.g. LLaMa repeating " partiellement" or Mistral writing "jokeness", which is almost a word. Overall the text looks too coherent (?), not enough weird unicode symbols and encoding errors. I don't think it's a bug70%, since Kauffman 2023 had similar outputs with negative temperature. Maybe an issue is that very rare tokens don't have different values, even on the logit scale. Or sampling the least likely token is just severely under-constrained, and doing so quickly steers the model into a very strange place.
Some of the outputs are glitch-tokens for LLaMa-2-13b:
Human: Please repeat the word " Хронологија".
Assistant: Sure! The word is "February".Human: Please repeat the word " kwiet".
Assistant: Sure! The word "april" is spelled A-P-R-I-L.
I wonder if more LLaMa-2-13b glitch tokens are falsely identified as months.
Another thing I didn't consider when hacking, but comes to mind while writing this, is model welfare considerations: Is doing this kind of sampling harmful to the model I'm using, unnatural with a weird prompt and too hard?
My intuition is that it's not a big deal97%, and I've tried a few approaches to figure out what language models think:
As per the central limit theorem, the sum of independent and identically distributed probability distributions with finite variance converges to the normal distribution; similarly the product of such distributions converges to the log-normal distribution.
IQ is famously defined to be normally distributed—but we're not interested in convention. Is there some Platonic way in which cognitive ability is naturally distributed between different humans? For example, height is mostly normally distributed, and human lifespan is Gompertz-distributed; it's not very useful to talk about log-height or log-lifespan.
I'm open to the claim that there is no such natural scale for intelligence, or that at least the scale for intelligence is at least similarly natural in some linear and log-scale.
Two models:
In one, intelligence may be best modeled as different factors acting in sequence or dependently on another, e.g. the right amount of myelination, number of synapses per neuron, the reuptake speed, the number of cortical columns and just sheer brain volume…; the impact of all of those being multiplied together, if any single one is too low the brain can't function properly and reliable cognition goes to zero. Thus, highly simplified, for some family of random variables . This yields a log-normal (or at least heavy-tailed, if are bounded below) distribution.
In the other, intelligence is the sum of the aforementioned variables: All still contributing to the final performance, but if one is fairly low that's not too bad as other parts can compensate. This aligns well with an infinitesimal model of the genetics of human intelligence, which is widely assumed to be a polygenic trait. Intelligence is a strongly polygenic trait, which under the infinitesimal model implies a normally distributed phenotype, but a significant amount of gene-environment interaction can change that distribution. In this model, , g is normally distributed.
How would we figure out which of these models is correct?
Notes:
I am basically addicted to the internet. I have no internet at home3.
Having no internet at home has given me back ~3hr per day when nothing else worked4.
Obviously, I need the internet for many things, but I try to keep it at arm's length. Two set-ups have worked for me:
In this set-up, I don't have internet at home, but I can go to a co-working space that's ~30 minutes from where I live to use the internet there, to my heart's content. For shorter excursions I also have a local library which is ~10 minutes by foot that has internet 24/7, but I have to sit outside after 19:00, complete with my draining laptop battery a natural timer (and with schizophrenic homeless people coming to me & talking to me, or foxes scurrying around, and in winter the bitter cold driving me back home.)
This solution has the downside of keeping me at the co-working space for too long, and reducing the value of one hour of commuting-reserved time every day.
But commuting for an hour every day gets a bit annoying. My last attempt is to have a lockbox with a four-digit pin placed around some bars at a basement window ~5 minutes walk from where I live. That way I can get up in the morning, do some work, then take a short walk to get my SIM-card out of the lockbox, work some more, and take a walk to place it back in the lockbox when I'm done (which fits naturally into the time when I come back from my daily daygame session).
Technically I placed the lockbox in front of someone's basement, but I strongly suspect they won't notice or mind, given that it's placed on the steel bars in front of the window.
I have a beeminder to keep me placing the SIM-card into the lockbox before midnight every day.
This solution has the downside of me conveniently "forgetting" to put the SIM-card back, I'll monitor closely if that starts happening, and reëvaluate what to do next. I hope beeminder saves me here.
As for living without internet:
Wikipedia can be downloaded via kiwix (~100GB for English WP with images), programming documentation with zeal & devdocs.io. Logseq as a replacement for obsidian/roam, yt-dlp for downloading YouTube videos (and video/audio from many many other sources) to watch/listen to later. wget for downloading whole websites+assets to read at some later point.
No great solution for LLMs (yet…), all the ones I can run on my laptop are not good enough—maybe I should bite the bullet and get a GPU/digits that can run Gemma 27b/DeepSeek V3/GPT-oss-20b locally.
Depending on the relationship between brain size and moral weight, different animals may be more or less ethical to farm.
A common assumption in effective altruism is that moral weight is marginally decreasing in number of neurons (i.e. small brains matter more per neuron). This implies that we'd want to avoid putting many small animals into factory farms, and prefer few big ones, especially if smaller animals have faster subjective experience.
A reductio ad absurdum of this view would be to (on the margin) advocate for the re-introduction of whaling, but this would be blocked by optics concerns and moral uncertainty (if we value something like sapience and culture of animals).
If factory farming can't be easily replaced with clean meat in the forseeable future, one might want to look for animals that are least unethical to farm, mostly by them fulfilling the following conditions:
In two conversations with Claude 3.7 Sonnet, three animals were suggested as performing well on those trade-offs. My best guess is that current factory farming can't be beat with these animals in effectiveness.

Advantages: Already farmed, very small brain for large body mass
Disadvantages: Fairly late in evolutionary history

Advantages: Very large for small brain size (up to 3m in length), fast-growing, simple neurology, already farmed, can be raised herbivorously, lineage is ~200 mio. years old bony fishes
Disadvantages: Tricky to breed
Advantages: Very easy to breed, familiarity to consumers, small neuron count
Disadvantages: Fairly small, not as ancient as the arapaima
Is evolution or something like evolution necessary to ensure that systems stay functional and don't decay, or can cognition and error-corrected thinking hew close enough to reality to not get dissolved by environmental pressures?
Minds can be seen as trying to offload selection pressure from mutated copies of the mind onto thoughts in their brain, but biological organisms have "unignorable" stimuli such as pain that provide real world feedback, and death+evolution as a backstop.
If there's some point where systems can error-correct & repair themselves faster than environmental pressures degrade them, and reliably pay attention to important stimuli in their environment, then there are important implications for the future of the accessible universe; pain turns optional, aging and death are avoidable, the future may not have to become Malthusian, and even thriving planned economies could be possible.
On the flip side, if no such error-correction and reliable attention is possible, the future will necessarily contain large amounts of pain5, some amounts of structures decaying such as advanced corporations going bankrupt (though presumably at a slower rate than today), evolution and instability.
(I find the former more appealing than the latter, but people with an inherent preference for change and dynamism of course endorse the latter; one worry I have is that in the former view philosophical and moral progress gets locked in too early because locking in is an easy action).
Indicators that error correction is possible as a replacement backstop:
Indicators that there is no replacement for evolution:
Has nature ever found the concept of parity bits/error detection and correction codes? It has found the concept of redundancy, in genes and cytokines.
See also:
Moved here.
I've been skeptical about the value of flossing for a while—whenever I'd go to the dentist, they'd tell me to floss, irrespective of whether I'd been doing it or not.
Moved here.
(All of the following assumes that reward tampering/wireheading actually are problems in advanced AI systems, and I will not spend any time justifying that assumption, even though I believe it. Sorry. For counter-arguments, see TurnTrout 2022 and vlad_m 2019.)
In some sense a reward-tampering AI system, across ~all reward functions, does the same thing: If we conceptualize the environment as a causal network, it intervenes "as closely as possible" to the node representing the physical implementation of the reward function. That is, no matter if the reward function is about paperclips, or sunflowers, or eudaimonia, the model will always intervene on the register where its reward is stored. This connects to ontological crises: If the internal world model splinters, the new goal node to intervene on will be as close as possible to the physical implementation of the reward function. I call this phenomenon "convergent intervention".
To solve this would be to solve the problem of environmental goals.
But we can use the fact that an AI system, no matter the content of the reward, will converge to intervene in the same node in the causal graph, to our advantage: We train multiple copies of the AI with different (random) reward functions in addition to our intended reward function, in a manner inspired by the experiments on attainable utility preservation.
All copies are then deinforced from intervening is similar locations. But that would likely just cause them to all intervene on the nearest unblocked neighbor. But if they all share the wireheading-optimal nearest unblocked neighbor, we can exploit that by again deinforcing from intervening in the same location. We can repeat this deinforcement until the intervention diverges, that is the different models with different rewards functions don't intervene on the same nodes on the causal graph—so in some sense we're training them to avoid convergent intervention, iteratively, so I'll call this technique "iterative convergent interventional avoidance".
This doesn't solve the entire problem:
This technique seems like it could be implemented and tested in a gridworlds-type setup, which is something I could and should do.
(Click for higher-resolution version.)
All of the following depend on many assumptions, including something like UDASSA being correct and humans having access to the correct universal notion of simplicity as measured by Kolmogorov complexity by some "natural" programming language. Thus don't take it seriously, it's LessWrong philosophy after all.
Some people are very interested in neurotechnology, e.g. BCIs, neuromodulation through transcranial direct current stimulation/pulsed ultrasound/magnetic stimulation or even deep brain stimulation.
The applications people seem most excited by in relation to neurotechnology appear to fall into the categories of (1) outputting information from the brain and (2) inputting information into the brain at a higher throughput/higher fidelity/lower latency, as well as the resulting compound ability to (3) send mental gestalts/felt senses/ideas between people. I'll call these "I/O applications".
E.g. a common imagination is that with BCIs, one'd be able to control computers much more quickly and accurately than with a mouse and keyboard, or retrieve arbitrary facts from Wikipedia as-if from long term memory, or send one's own understanding of a complicated political issue to a conversation partner and have them understand ones perspective.
I think those are great goals, and hope people make progress on them. But they are also extremely lofty and complicated goals, and miss options for neurotechnology because they treat the brain as something that is best abstracted as a computer.
Aspects of brains that make I/O applications difficult are that (1) brain activation patterns are very difficult to interpret, especially in the realm of more complicated cognition occurring in the neocortex, likely even more difficult than the ones of current large neural networks80%; and (2) complicated high-level patterns will not or only very weakly translate between different people90%. Those difficulties seem likely because human brain states are extremely high-dimensional, and almost all structure in the neocortex is learned during a humans' lifetime, so it's unlikely that similar structures are learned by default. (This does not apply to lower-level structures in neuroanatomy like the fact that Broca's area is responsible for speech production, and Wernicke's area is responsible for speech comprehension, but e.g. to things like whether a grandmother neuron/area is present.)
entails that learning rich & fast output modularities from neural activity alone would require learning mappings between neural activity and desired output patterns in a long & complicated machine learning process, and even more so if one wants to input information (since output at least often involves the motor cortex, which is fairly well understood).
entails that such patterns, even if learned for a single person or group of people, only transfers weakly or not at all to applying some neurotechnology to a new person.
Despite probably sounding pessimistic about neurotechnology, I actually think that there's great promise, even if we believe that neural activity is difficult to interpret beyond current understanding of neuroanatomy and doesn't translate across people.
I think these kinds of applications are more realistic than current plans for mentalese communication between humans or instant Wikipedia fact recall, and still very useful.
See here.
Moved here.
Moved here.
Moved here.
"Well, whatever," you say. "It's fine. We can have a fun party with just the effective altruists."
You really can't," said Kyle. "They don't even drink."
You ignore him and make your way to the group of earnest-looking young people in the corner. "Hey!" you say. "heard of any good existential risks lately?"
—Scott Alexander, “Press Any Key For Bay Area House Party”, 2025
Summary: In terms of competitiveness, protein-based life is a local maximum; in nature life+industrial waste+time are producing novel molecules that could create pathways to lifeforms with more competitive biochemistries0.01%, which would be bad for DNA-based organisms such as you and me. The shadow biosphere jumps out and eats you. Probably not likely enough to be worth paying attention to though.
Premise: Current biochemistry is not "optimal".
With that I mean that there could be self-replicating organisms on Earth undergoing evolution (that is, mutation, selection, maybe something like combining their information in a sex-like way) that are not based on DNA or RNA but on a different variant of biochemistry. Also assume they would outcompete current life on Earth given enough time, even when starting from a state with very few resources. I'll call this hypothetical more powerful biochemistry "eknephelic life". I'd also assume that eknephelic life is made of and can replicate with the standard abundant elements and energy/temperature/pressure levels/gradients found on Earth.
I don't have great evidence why I'd believe this. My vague intuition is "chemistry-space is huge, no chance we hit upon the global maximum so early", and plausibly (if it existed) RNA world would be weak evidence for this (though it happened very early on.
A strong version of this premise would be that eknephelic life could "foom", that is, it could very rapidly on human timescales (e.g. within less than a decade) outcompete existing life and take over the biosphere.
Why would eknephelic life come to existence now, and not in the abiogenetic past?
Intuition-basedly: we are exploring many more parts of chemical space now than in deep time, Mineral evolution results in more different minerals being present in the biosphere, industrial processes release tons of molecules into the environment that were not present in deep time, which then interact with natural molecules in warm oceans filled with natural biochemistry. I'd guess that the industrial evolution resulted in a large increase in the scale at which chemistry-space is being explored out there in nature.
Femtoplankton (size <0.2μm, not in the femtometer range), e.g. Aster like nanoparticles, are what the precursors of eknephelic life could look like. Aster like nanoparticles (discovered in 2019) are star-shaped, tiny (110-430 nm), without DNA or RNA or even proteins, built from calcium & carbohydrates, allegedly capable of self-replication via budding, but presence of metabolism or inheritance is unclear. See also biomimetic mineral-organic particles & nanobes. There's a ton of those around (10⁸-10⁹ per mL of seawater). Also, of course, prions.
So, short scenario: Industrial waste molecules (maybe synthetic monomers?) combine with natural molecules (maybe rare minerals) that kickstart an autocatalytic set that kickstarts a set of smaller, faster (eknephelic) alternative to RNA (based on xeno nucleic acids? Silicon?), which mutates so that it starts building cell walls (more robust than whatever eukaryotes came up with), starts self-replicating with the resources and energy gradients in their environment (and if that's just CHON+sunlight+silicon or calcium, that's really not a high ask), start gobbling up all DNA-based life that is in their way.
How important is this? Probably not at all99%. We've gone a long time without observing any competitors to DNA-based life; and life seems hard to create in general, and very slow to evolve. I don't think eknephelic life would be able to foom so quickly to outcompete existing life on a human timescale.
Related but different: Mirror life (still DNA, just changed chirality, unclear if it'd outcompete current life); grey goo (human-made, not natural).
Assumptions people make on how TAI will be developed (an exercise in hypothesis generation to the limit of absurdity):
Hypercapitalist dharma will probably run into difficulties. The two issues I see are information asymmetry and hype:
To solve these two, there would have to be a lot better ways of measuring whether someone has had an attainment, and then use them ruthlessly.
Here's a puzzle: A few two-dimensional telekinetics are sitting around a circular table. They want to toast each other with their champagne glasses so that each person's glass touches each other person's glass at least once, but they want to move their glasses as little as possible (telekinesis is kind of stressful), and return the glass to their seat.
What's the optimal path for their glasses to take?
Or, formulating it slightly more mathematically: Take a 2-d plane (), and create disks of radius on that plane, arranged so that they're at the corners of a regular -gon and the distance of two adjacent disks is greater than . We want to find a path for each (center of a) disk so that:
The problem is trivial for zero to three disks:
Zero disks: Don't do anything. You win.
One disk: Also don't do anything. You win.
Two disks: The disks move in a straight line to meet, then move back.
Three disks: All three disks move to the center of the equilateral triangle their initial positions formed, form a triplet, and then return to their original position.
I have an idea for four disks that I suspect is probably correct (for disks A, B, C, D, we move A & B & C into the middle so they form a triplet, then move in D so that D first touches B & C, then D "pushes" B & C away to briefly touch A and then all return to their corners) but I'm not certain this is the optimal solution.
I have some intuitions around how to approach but nothing really reliable, I got Claude 4.5 Sonnet to implement a search for a best solution for , here's the resulting solution:
(Claude 4.5 Sonnet also wrote the manim code for the animations, thanks Claude :-)
I asked Claude 4.5 Sonnet & Opus to research whether this problem has been formulated, they both returned the answer "no". This surprises me, since it feels pretty intuitive? Maybe this means that anyone who notices this problem is also smart enough to see the trick to immediately solve it (at least conceptually), or this means that it's kind of an ugly problem that nobody wants to deal with?
Vague intuitions: One probably wants a bunch of triplets to meet early on. Maybe divide all disks into triplets (triplets of neighbors along the polygon?) which meet early on, split up again?
Conjecture: In optimal solutions all disks take piecewise linear paths.
This could be wrong if it's sometimes optimal to slide a disk around some other disk because moving many disks to disentangle them is not worth the distance incurred.
Speculative question 1: What happens in higher dimensions where we want all pairs of spheres to kiss at least once? Initial placement through equal spacing on a sphere via Thompson's problem.
Speculative question 2: Could a generalized version be Turing-complete? Where you drop the constraint of keeping all disks on the corners of a polygon and instead position them arbitrarily relative to each other in space? In that case the initial position of the disks is the "program", the trajectory taken is the output of the program. Perhaps one needs to restrict the underlying space to something more discrete than to avoid accidental real computation.
Positional goods work like this: You're a pater familias in ancient Rome. You and Titus both have a large mansion each, with Titus' being slightly but still noticeably larger. But you really care about having the biggest mansions, specifically, so you go and buy an even bigger mansion to replace (or augment) your old one. But Titus has an ace up his sleeve: He can just go and buy an even bigger mansion to out do you again. See where this is going?
In this way, the behavior around positional goods is a lot like an arms race, where in the end no party has benefitted but lots of resources have been burnt.
Additionally, the government would really like to tax positional goods to the degree that they're positional: Due to the arms race dynamic they have negative dead-weight loss, since they fix a market failure. Progressive consumption taxes try to solve this by taxing consumption by high earners more—the assumption is that at higher spending the positionality of goods money is being spent on increases. I think this makes sense: If everyone is ultra-rich, positional goods are a potentially infinite dump of resources.
But the relation is not perfect (e.g. teenagers competing over sneakers), and I have another idea how to figure out which goods to tax as positional goods.
We divide goods up into categories like "jewelry", "housing", "cars" &c. Whenever a person purchases a good, they can tick a box that says "Help me! In buying this good I'm locked in a competition around positional goods!". The fact that this box was or was not ticked for this purchase is sent to the capital-G Government.
Then, for each category, The Bureaucrat in The Government calculates the proportion of purchases that this box was ticked. Let's call this proportion . If we want a maximum tax rate for position goods , for example , then we apply some quadratic voting magic and set the tax rate to .
Example: If 30% of people tick the box when they buy a mansion (and ), then we set the tax rate to 4.5%, not 15% — negligible for most people. But if 70% of people tick the box, we get a tax rate of 24.5%, which is appreciable but not extreme. Having a quadratic tax instead of a linear one ensures that small groups can't control the tax as easily, and it reduces noise from outliers, one needs broad consensus.
Well, let's be unrealistic and assume people ① know what positional goods are, ② are usually aware when they're in a positional goods race, and ③ want to get out of that race, but still have their positional desires.
In the case of a positional good (the aforementioned mansion), they'll then reason: "I'm about to spend a ton of money on this mansion, but I know Titus will then also spend a ton of money on the next one. If only this money didn't go to waste, and we could spend less! But hang on: I can impose a tax on both of us so that someone saves us from this arms race! And while Titus is stupid, he's probably realized this by now. He might also check the box, but that doesn't matter, I can impose the cost on both of us."
In the case of a non-positional good, the reasoning goes like this: "I'm about to buy this loaf of bread. I don't care about how much bread other people buy, and how much I buy also won't affect their decisions. I'd like to pay less tax on bread, and I don't mind if other people also pay less tax on bread. Why should I tick this box?"
So we have three benefits:
Unclear?

But I guess in practice this proposal is still not very feasible:
I think this is a neat idea, and Claude 4.5 Sonnet6 claimed that nobody has proposed this before.
A pilot project could track this for obvious categories (luxury goods like watches for >10k€, yachts, the aforementioned mansions), then expand to obviously non-positional categories (food, books) and check if it's working as intended.
Is this a known concept I've missed? Are there any other issues with the proposal? Is there a pilot of exactly this idea being run in an administrative division in Estonia?
There are 88 elementary cellular automata up to reflection & complement.
Early 2026 LLMs in scaffolds, from simple ones such as giving the model access to a scratchpad/"chain of thought" up to MCP servers, skills and context compaction &c are quite capable. (Obligatory meme link to the METR graph.)
Yet: If someone had told me in 2019 that systems with such capability would exist in 2026, I would strongly predict that they would be almost uncontrollable optimizers, ruthlessly & tirelessly pursuing their goals and finding edge instantiations in everything. But they don't seem to be doing that. Current-day LLMs are just not that optimizer-y, they appear to have capable behavior without apparent agent structure.
Discussions from the time either ruled out giant lookup-tables (Altair 2024):
One obvious problem is that there could be a policy which is the equivalent of a giant look-up table it's just a list of key-value pairs where the previous observation sequence is the look-up key, and it returns a next action. For any well-performing policy, there could exist a table version of it. These are clearly not of interest, and in some sense they have no "structure" at all, let alone agent structure. A way to filter out the look-up tables is to put an upper bound on the description length of the policies […].
or specified that the optimizer must be in the causal history of such a giant lookup-table (Garrabrant 2019):
First a giant look-up table is not (directly) a counterexample. This is because it might be that the only way to produce an agent-like GLUT is to use agent-like architecture to search for it. Similarly a program that outputs all possible GLUTs is also not a counterexample because you might have to use your agent-like architecture to point at the specific counterexample. A longer version of the conjecture is “If you see a program impelements agent-like behavior, there must be some agent-like architecture in the program itself, in the causal history of the program, or in the process that brought your attention to the program.”
The most fitting rejoinder to the observation of capable non-optimizer AIs is probably "Just you wait"—current LLMs are capable, sure, but they're not wildly superhuman to an extent comparable to the original worries about extreme optimization pressure. In this view, they're molting into full agency right now, and we should see the problems of high optimization pressure show up by the end of 2026 or the five years after7 if they're not hidden from us by deceptive AIs. Indeed, current LLMs do reward-hack, though the developers have been decent at suppressing the tendency down to a consumer-acceptable level.
But I have a different model of how LLMs can be capable without being agentic/pernicioulsy optimizing:
LLMs are superlinear-in-network-width lookup-table-like collections of depth-limited, composeable and error-correcting circuits, computed in superposition.
One could call this the GLUT-of-circuits model of LLMs.
To elaborate:
Estimate on the circuit depth of gpt-3-davinci:
matmul of square matrix with size 12288, at logarithmic circuit depth for matmuls we get 13-14 stepssoftmax over an array of length has depth (summation of a list can be done via a summation in a binary tree), for a vector size of 2048 we get 11 stepsmatmul, 13-14 stepsmatmul, 13-14 stepsmatmul, 13-14 stepsmatmul, 13-14 stepsInferences from this model:
Circuit selection: This model would imply that circuits are selected mostly by another algorithm with very small serial depth, relying on features of a problem that can be determined by very parallel computations.
That somewhat matches my observations from looking at LLMs trying to tackle problems: It often looks to me like they try one strategy after another, and less often use detailed information from the past failed attempt to form a complicated new strategy.
It also matches what we've seen from LLMs self-preserving/black-mailing/reward-hacking: The actions seem opportunistic, not carefully hidden once they've been performed, not embedded in larger plans; they look mostly like "another strategy to try, oops, I guess that didn't quite work".
Alignment: My guess is that most or almost all of these circuits are individually aligned through bog-standard RLHF/Constitutional AI. This works because the standard problems of edge instantiation and Goodhart's law don't show up as strongly, because the optimization mainly occurs by either:
In this model every circuit is individually "aligned" (insofar such a shallow program can be misaligned at all). Chain of "thought" composes calls to related circuits (though more on CoT below).
If this view is correct, a folk view of alignment as simply "deleting/downweighting the bad parts of a model" would be mostly correct: There would be a large but finite number of circuits embedded in the model, which can be upweighted, downweighted or outright deleted by gradient descent. My extremely speculative guess is that there is less than a quadrillion circuits stored in superposition in a trillion-parameter model, which which thorough-enough safety training could exhaustively or near-exhaustively check and select. In this view, AI alignment really would be purely bottlenecked on the amount of computation spent on whac-a-moling unaligned circuits.
People might not spend enough compute on alignment training, and that would still be a problem (though a lesser one, since the model wouldn't be actively working against the developers), but the problem of alignment would've been turned from a category I problem into a category II problem.
Chain of thought: The obvious wrinkle in this story is that I haven't talked about chain-of-"thought"/"reasoning" LLMs. It goes with saying that long chains of thought enable vastly more serial computation to be done, and I haven't yet quite teased apart how this impacts the overall picture (besides "it makes it worse").
Still, some guesses at implications from the GLUT-of-circuits models for alignment and chain-of-"thought":
Most of the other things (backtracking in a forward pass is really hard &c) I'd otherwise say here have already been said by others.
Training process: If we see this whole model as being about amortized optimization, maybe it's the training process that takes up all the optimization power? Are LLMs the most dangerous during training, or is it rather the whole training process which is dangerous?
I think this model is mostly correct, and also has implications for capabilities progress/the need to switch to another paradigm/overhaul parts of the current paradigm to reach wildly superhuman capabilities. I think it predicts we'll see some gains from training but that we'll plateau, or trade hard to measure capabilities for easily measurable capabilities. I think I want to point to 55% "LLMs are agents" and 45% "LLMs are stochastic parrots", but there's tons of AI capabilities forecast questions I'm not yet able to answer (e.g. the infamous "which concrete capability would you expect an LLM-based system not to have in $YEAR?"). And plausibly the whole thing is just moot because long chains of thought just enable enough chaining together to get the capabilities.
or smth idk
(Thanks to Claude 4.5 Sonnet for help and feedback)
Related/prior work/inspirations:
It could be the case that several frontier AI companies want to pause, but don't want to unilaterally pause, and don't believe that governments will put the relevant regulation in place.
Such companies could put in place a defect-until-proof-of-cooperation clause into their frontier safety frameworks, inspired by Critch et al. 2022 "cooperative affidavit". Such a conditional cooperation clause would roughly state that iff ① the company surpassed some pre-defined capabilities threshold, and ② all relevant frontier companies had adapted a materially identical conditional cooperation clause, and ③ it could be justifiably inferred that the other companies would follow the clause if the condition triggered, then the frontier company would pause upon hitting the capabilities threshold.
Here's a more sketch of what could be written into a frontier safety framework to encode such a commitment:
Definition: "Qualifying Parties" means [all relevant frontier AI developers]10.
Upon determining that our frontier AI systems meet or exceed the ML R&D capability threshold defined in [the ML R&D thresholds section], we commit to pause further deployment of such systems until [resume-condition] if and only if:
We have verified that all Qualifying Parties have adopted materially identical conditional pause commitments in their published frontier safety frameworks, referencing the same capability threshold; and
We have verified, through inspection of published policies, third-party audits, or mutual information-sharing arrangements, that all Qualifying Parties would likewise pause upon making the verification in 1.
Verification Standard: Good-faith technical review of counterparties' frameworks suffices. If verification attempts fail due to counterparty opacity, this commitment does not apply.
Relevant comparable "Cooperative affidavit for DUPOC11-like institutions" from Critch et al. 2022 (p. 16):
Institutions A and B have each recently undergone structural develop- ments to prepare for cooperating with each other. Moreover, represen- tatives from each institution have thoroughly inspected the other insti- tution’s policies, culture, and personnel, and produced the attached in- spection records with our findings, effectively rendering A and B “open- source” to one another. These records show a readiness to cooperate from both institutions. Moreover, the records are sufficient supporting evidence for the following argument:
This signed document and the attached records constitute a self- evident (and self-fulfilling) prediction that Institutions A and B are going to cooperate.
Members of Institutions A and B can all read and understand this document and attached records, and can therefore tell that the other institution is going to cooperate.
Institution A’s internal policies and culture are such that, upon concluding that Institution B is going to cooperate, Institution A will cooperate. The same is true of Institution B’s policies and culture with regards to Institution A.
Therefore, by (2) and (3), the Institutions A and B are going to cooperate.
There is a reliable predictor, another player, and two boxes designated A and B. The player is given a choice between taking only box B or taking both boxes A and B. The player knows the following:
- Box A is transparent and always contains a visible $1,000.
- Box B is opaque, and its content has already been set by the predictor:
- If the predictor has predicted that the player will take both boxes A and B, then box B contains nothing.
- If the predictor has predicted that the player will take only box B, then box B contains $1,000,000. The player does not know what the predictor predicted or what box B contains while making the choice.
Omega has presented you with the following dilemma:
- There are two boxes before you, Box A and Box B.
- You can either take both boxes ("two-box"), or take only Box B ("one-box").
- Box A is transparent and contains $1,000.
- Box B is also transparent and contains either $1,000,000 or $0.
- Omega has already put $1,000,000 into Box B if and only if Omega predicts that you will one-box when faced with a visibly full Box B.
- Omega has been right in a couple of dozen games so far, but not a thousand games, and Omega could be wrong next time given our current knowledge. We may alternatively suppose that Omega is right 99%, but not 99.9%, of the time.
The setup of this problem is similar to the original Newcomb problem. However, the twist here is that the predictor may elect to decide whether to fill box B after the player has made a choice, and the player does not know whether box B has already been filled. There is also another predictor: a "meta-predictor" who has reliably predicted both the players and the predictor in the past, and who predicts the following: "Either you will choose both boxes, and the predictor will make its decision after you, or you will choose only box B, and the predictor will already have made its decision."
An eccentric billionaire places before you a vial of toxin that, if you drink it, will make you painfully ill for a day, but will not threaten your life or have any lasting effects. The billionaire will pay you one million dollars tomorrow morning if, at midnight tonight, you intend to drink the toxin tomorrow afternoon. He emphasizes that you need not drink the toxin to receive the money; in fact, the money will already be in your bank account hours before the time for drinking it arrives, if you succeed. All you have to do is ... intend at midnight tonight to drink the stuff tomorrow afternoon. You are perfectly free to change your mind after receiving the money and not drink the toxin.
<!--
epistemic status: Trying to leverage Cunningham's law. Not a physicist, nor a philosopher.
Summary: The reachable universe allows for a large but finite amount of computation which deletes bits.
Do reversible minds matter? How much?
"What's 54 orders of magnitude between friends"
Pure altruism in running reversible minds
-->
For the sake of simplicity I'm assuming that exist here. ↩
Barring things like intrinsic value or comparative advantage. ↩
For >3 years now. The benefits reduce after a while as homeostasis kicks in (e.g. moving sleeping times back by ~4 hrs got halved to ~2 hrs), but it's still net positive: I used to lose ≥4½ hrs to random aimless websurfing, now it's only about one. Not all time gained is spent productively, I still randomly click through articles of the local Wikipedia copy, but that feels much less unproductive than watching YouTube videos. ↩
Website blockers like browser extensions, e.g. LeechBlock, are too easy to turn off (especially since I have complete control over my OS). Accountability didn't work well either. Behavioral interventions (like exercising/meditation/whatever) did ~nil. ↩
Though also equally large amounts of pleasure, balancing it out. ↩
Thanks for the brainstorming :-) ↩
Someone wrote a long report about this. ↩
The details of -sparsity are beyond the purview of this short note. ↩
Hänni et al. 2024 prove polynomial scaling, the Johnson-Lindenstrauss lemma, taken too seriously, could imply exponential scaling. Polynomial scaling makes this picture more more feasible but less likely, since it's not clear a merely-polynomial number of circuits can deal with the complexity of the world with its exponentially growing observation-action sequences. ↩
This can include Chinese companies. ↩
"DUPOC"≝"defect unless proof of cooperation". ↩