author: niplav, created: 2024-04-22, modified: 2025-02-07, language: english, status: in progress, importance: 5, confidence: likely
In which to compare how similarly programs compute their outputs, naïvely and less naïvely.
I've now realized that this post is not very useful, because the methods outlined only work for programs you can run, and once you've run two programs you can just determine what their output is. I still think this is interesting to think about, both from a god's eye view perspective à la Ω, but it's not very useful for embedded agency type thinking.
Attention conservation notice: Premature formalization, ab-hoc mathematical definition.
In the twin prisoners dilemma, I cooperate with my twin because we're implementing the same algorithm. If we modify the twin slightly, for example to have a slightly longer right index-finger-nail, I would still cooperate, even though we're different algorithms, since little enough has been changed about our algorithms that the internal states and the output are basically the same.
It could be that I'm in a prisoner's dilemma with some program that, given some inputs, returns the same outputs as I do, but for completely different "reasons"—that is, the internal states are very different, and a slight change in input would cause the output to be radically different. Intuitively, my similarity to is pretty small, because even though it gives the same output, it gives that output for very different reasons, so I don't have much control over its outputs by controlling my own computations.
Let's call this similarity of two algorithms the logical correlation between the two algorithms (alternative terms "include “logical influence,” “logical correlation,” “correlation,” “quasi-causation,” “metacausation,” […] “entanglement”[,] “acausal influence”"). I take this term from Demski & Garrabrant 2020:
One idea is that exact copies should be treated as 100% under your “logical control”. For approximate models of you, or merely similar agents, control should drop off sharply as logical correlation decreases. But how does this work?
—Abram Demski & Scott Garrabrant, “Embedded Agency” p. 12, 2020
Similarly:
The reasoning behind cooperation does not involve a common cause of all collaborators' decisions. Instead, the correlation may be viewed as logical (Garrabrant et al., 2016): if I cooperate, then this implies that all other implementations of my decision algorithm also cooperate.
—Caspar Oesterheld, “Multiverse-wide Cooperation via Correlated Decision Making” p. 18, 2018
There isn't yet an established way of estimating the logical correlation between different decision algorithms.
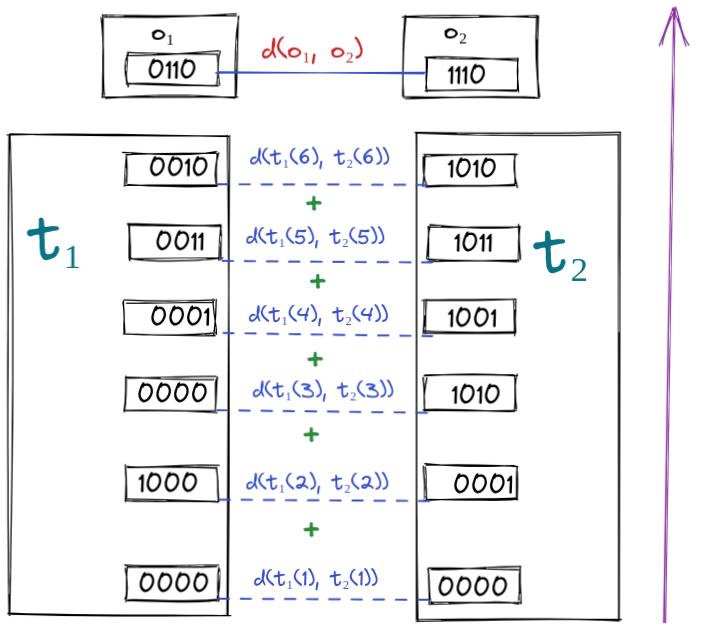
Thus: Consider the some naïve formula (which we'll designate by 1) for logical correlation2: Something that takes in two programs and returns a number that quantifies how similarly the two programs compute what they compute.
Let a program be a tuple of code for a Turing machine and intermediate tape states after each command execution. We'll treat the final tape state as the output, all in binary.
That is , with and . Let be the number of steps that takes to halt.
For simplicity's sake, let's give (the tape state upon halting) the name , the output.
Let be two halting programs, are the number of steps it takes to halt, and the last tape states (outputs) of the two programs.
Then a formula for the logical correlation of , a tape-state discount factor 3, and a string-distance metric could be
The lower , the higher the logical correlation between and .
Let's take a look at the equation again, but this time with some color highlighting:
The fundamental idea is that we first compute the distance of the two outputs. We then go backward through the trace of the two programs, adding up the pairwise differences of the traces at each timestep, potentially discounting the differences the farther they lie in in the "past" of the output/further towards the start of the computation.
Finally, we subtract the inverse of this (discounted) sum of trace differences from the output difference4.
The value of the exponential function here can maximally be 1 (since the smallest value of the sum is zero) and will always be greater than zero. Thus, since we're subtracting a number ≤1 from , the resulting logical correlation must be . That implies that for three programs with the same output, their logical correlations all lie in that range. That also means that if , then it's the case that .
Or, in even simpler terms; "Output similarity dominates trace similarity."
One might also want to be able to deal with the fact that programs have different trace lengths, and penalize that, e.g. amending the formula:
Does this fulfill our desiderata from earlier? I'll assume that the string distance is a metric, in the mathematical sense.
Proof:
Since is a metric, .
Symmetry is trivially true if we assume that is symmetric.
The minimal logical correlation is 0.
This is true, because:
Thus we have a sum of products of only positive things, which is in turn positive itself.
But, unfortunately, it isn't the case that if , then . Thus is only a pseudometric.
Consider, for example, two programs that both write a to the starting position on the tape and then halt, but with the difference that moves left and then right in the first two steps, and moves right and then left in the first two steps. Both programs have the same tape-state trace, but are not "equal" in the strict sense as they have different source codes.
You might now complain that this is vacuous, since the two programs have no relevant functional difference. That's true, but I suspect there's some trickier edge cases here where randomly initialized tapes can have very different (or in other cases equal) tape-state traces. If you find an equivalence class of programs that are just vacuously different, I'd be interested in hearing about it.
I think that the naïve formula is too naïve. Reasons:
I think one can create a better (though not perfect) way of determining logical correlations based on (something like) Shapley Values and possible tape-permutations.
We'll inherit the basic setup from the naïve formula, but now we won't determine the logical correlation of the whole outputs . Instead we pick one bit from each output, say for some .
This formula is based on the assumption that Shapley values of tape cells over time are a kind of fingerprint of the program as it runs, and as such can be compared with some distance function akin to in the naïve formula.
We treat each tape state of a Turing machine as a set of players, which can play either or (the two states each cell on the tape can assume).
Then we compute the Shapley value for each tape state on the bit produced down the line by the Turing machine. To recap, the Shapley value assumes that there's a set (with ) of players, and a function for all subsets of players—in this case the execution of the program from until it halts. It's assumed that .
People sometimes like to claim that the Shapley value is some kind of Platonic ideal of measuring contribution. I don't know about that, but it has some nice properties that uniquely identify it.
The Shapley value for a player is then computed with the following equation:
Two conceptual difficulties present themselves:
1. can be solved by setting the null action to the tapestate produced by the program preceding the tapestate. I imagine this as a tapestate being able to "decide" to flip to the opposite bit before the program resumes, which counts as participating. We'll designate the function of letting a program continue running from a timestep until halting as .
(Note that it can very well be the case that a cell flipping its tape bit can have a negative Shapley value, e.g. if the output bit is one if the input bit does nothing, and zero if the input bit is flipped. This felt like a problem to me for a while, but now I would guess it's not an issue, and is just a genuine behavior of the program that can be compared to the other one. I continue feeling a bit confused about whether there's something worth fixing here.)
For 2., my best solution is to be (overly?) expansive in which tape cells are considered as potential contributions: Let's call the "leftmost" tape cell reached by a program on a Turing machine during the whole execution and the "rightmost" one ( for "frontier").
Then the subrange indexed of the whole tape is a range of natural numbers , abbreviated as .
Cells that haven't been "reached" yet by the program (or never will) automatically have a Shapley value of 0, that just falls out of the formula.5 Because we're taking the biggest possible "reached envelope" on the tape the tape segments for both programs have the same size.
So, for a bit in the output of the program , at some timestep , we get a list of Shapley values:
We'll call the Shapley value profile of a program at a timestep .
returns… a list of real numbers. So if we evaluate the Shapley value profile of two tape states for two different programs, we have to compare two same-length lists of real numbers and figure out how similar they are.
There are many ways to do so. I don't have a particular favorite, but for convience let's pretend we take the element-wise mean-squared error and call it a day.
I'll designate whatever difference measure is decided on as , just as earlier.
If we just use the difference between Shapley values for intermediate tape states, we won't have solved the first problem of the naïve formula: Direction-reversed programs are evaluated as being extremely dissimilar, even though they are very similar.
As hinted, I don't have a great solution to this, but my current best approach is to look at permutations of one of the tapes, and choose the one which best "matches up" the two Shapley value profiles with each other. E.g. for from earlier we'd compare the two programs using the permutation that reverses the tape of .
It's important that this permutation be chosen once for all timesteps.
I don't like this solution. Permutations are too permissive, and two programs where is best modeled as being pairwise flips of neighboring cells of are, intuitively, quite dissimilar.
My current best idea is to penalize permutations for complexity, e.g. by preferring permutations that can be constructed from few pairwise swappings (one generating set of the symmetric group). But that would strongly penalize "natural" very similar programs, such as . If anyone here has good alternative ideas, hit me up.
Phew! That was a lot. Putting it all together, in a similar framework as with the naïve formula, yields6:
with
If the two output bits are different, "start" with the logical correlation being 1. Go through the tape states backwards in terms of the two programs being run, back to the first "shared" program state. For each tape state, compute the Shapley value profile. Permute one Shapley value profile that it "best" matches up with the other one. Compute the difference of the Shapley value profiles, and sum them up.
The bigger the summed diffence, the smaller the exponent of the negative of that distance. The largest possible value of is , the smallest possible value is 0—in cases where and the sum of differences is zero.
I see one clear indicator that this hasn't been ironed out yet: If computes an output by first computing the "left half" and then the "right half" (in terms of location on the tape relative to the starting position), and computes first the "right half" and then the "left half", but compute both halves in very similar ways, then they should be very logically correlated, but the less naïve formula will tell you that they're quite different. (Which is just a version of the tape permutation, but over runtime.)
I don't know how to account for time permutation without even more ugly hacks.
The formulae I cobbled together are pretty specialized to Turing machines, and lack desired features. Some possible alternatives, which I'm not fond of for various reasons:
Suggested by GPT-4. Stands for joining, combining, uniting. Also "to suit; to fit", "to have sexual intercourse", "to fight, to have a confrontation with", or "to be equivalent to, to add up". ↩
Actually not explained in detail anywhere, as far as I can tell. ↩
Which is needed because tape states close to the output are more important than tape states early on. ↩
Together with adding one to avoid same logical correlations for programs with different outputs differences. ↩
I have the suspicion that this whole thing isn't actually a problem and one can just compare permutations of the whole infinite tape, but I don't want to take any chances with weirdnesses around permutations of infinitely many elements, or the mean-squared error between infinitely long lists. Also it's nice to be able to actually implement the solution. ↩
挧 is a ghost character, and as such has no previously assigned meaning. ↩